

在前一篇文章中,我們討論了在不平衡資料的情況下,如何有效衡量二元分類模型的好壞,也提到了一些常見的模型訓練方法,比如說:複製更多陽性個體 (Oversampling),或者是刪除陰性個體 (Unsersampling),使得陽性與陰性個體的比率達到 1:1;另外,也可以根據原本陽性樣本的分佈特徵,產生出分配相似的合成陽性樣本 (Synthetic Sample)。實際上,「產生合成樣本」跟 Oversampling 其實是很類似的,因此我們將在這篇文章中介紹幾種常見的 Undersampling 跟 Synthetic Sample 的方法。
SMOTE:產生相似的合成樣本
SMOTE (Synthetic Minority Oversampling Technique) 是最有名的樣本合成方法,這個演算法的概念很簡單:
- 找出與陽性個體 $latex \mathbf{x}_i$ 的最近的 k 個陽性鄰點 (k-nearest neighbors)
- 在 k 個鄰點中隨機選擇一個,稱作 $latex \mathbf{x}_j$,我們會利用該鄰點用來生成新樣本
- 計算 $latex \mathbf{x}_i$ 與 $latex \mathbf{x}_j$ 的差異 $latex \Delta = \mathbf{x}_j – \mathbf{x}_i$
- 產生一個 0 – 1 之間的隨機亂數 $latex \eta$
- 生成新的樣本點 $latex \mathbf{x}^{(new)}_i = \mathbf{x}_i + \eta \Delta$
如下圖所示,最左邊為原始資料;中間圖深色的個體是被用來找 k-nearest neighbors 的陽性個體,此處假設我們選擇 k = 3,則對於這兩個點 SMOTE 演算法會先辨認出最近的 3 個鄰近點,接下來會隨機挑選其中 1 個鄰點用來產生新樣本,最後會在被挑到的個體與對應鄰點的連線上隨機產生一個新的個體,並當作這個個體是陽性的;當我們選擇了很多不同的個體去找出 k-nearest neighbors 以及合成新樣本後,最後會的結果會像右圖所示。

SMOTE 在分類表現上通常可以給我們不錯的分類結果,但最大的缺點在於可能會讓算法對於「特徵重要性」 (Variable Importance) 失真。因此,如果你用了 SMOTE 這樣的方法,分類模型的解釋性通常會大幅降低(合成樣本… 聽起來就很難讓人接受)。
Tamek Links:刪除邊界上的陰性個體
Tamek Link 是一種常見的 Undersampling 方法,他的概念很簡單:刪除與邊界上陽性個體很靠近的陰性個體,直到每一個陽性個體附近的最近鄰點 (Nearest Neighbor) 都是陽性的,其過程如下所示:最左邊是數據的原始樣貌,其中紅色點為陽性個體,灰色點為陰性個體;中間圖代表我們會找出所有最近鄰點是陰性的陽性個體,並將該陰性鄰點刪除,如果刪除完一次還是有陽性個體的最近鄰點為陰性,則再次刪除該陰性鄰點;持續這個過程,最後就會得到所有陽性個體的最近鄰點都是陽性為止,如最右圖所示。
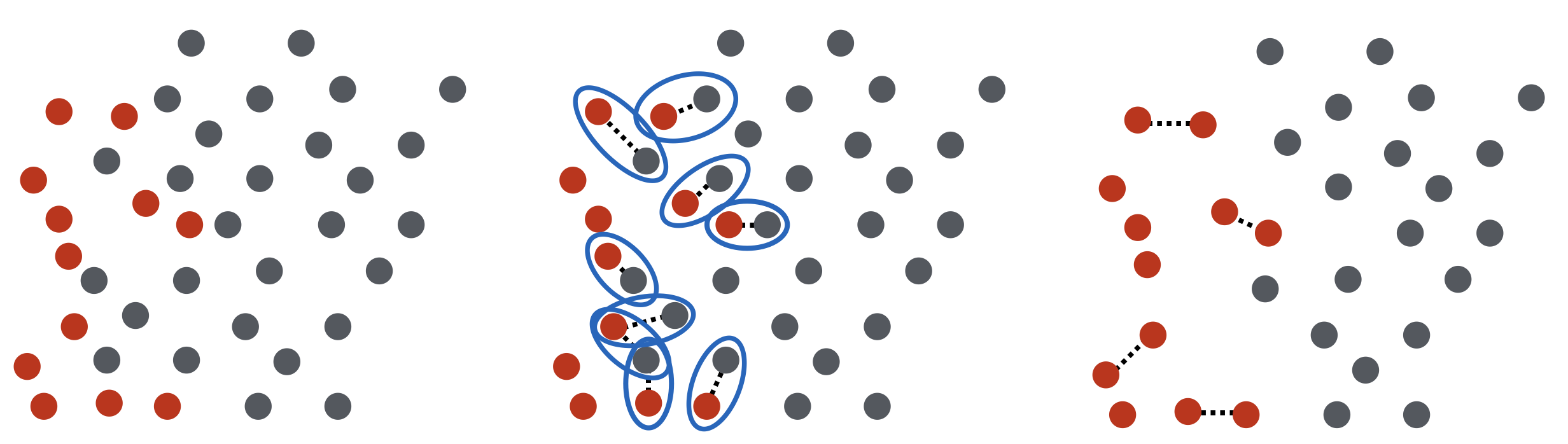
Tamek Link 是這個演算法的核心,一組 Tamek Link $latex (\mathbf{x}_i, \mathbf{x}_j)$ 滿足以下條件: $latex \mathbf{x}_i$ 與 $latex \mathbf{x}_j$ 屬於不同類別,且不存在任何一個資料點 $latex \mathbf{x}_k$ (可以屬於任何類別) 使得距離 $latex d(\mathbf{x}_i, \mathbf{x}_k) < d(\mathbf{x}_i, \mathbf{x}_j)$ 且 $latex d(\mathbf{x}_j, \mathbf{x}_k) < d(\mathbf{x}_i, \mathbf{x}_j)$。通常,Tamek Link 落於兩個類別的邊界或是雜訊較高的區域,透過刪除 Tamek Link 的陰性個體,我們可以得到較容易進行分類且較平衡的資料集合。然而,如果資料陽性與陰性的界線分野不是很清楚的話,就算刪除了陰性個體可能還是很難找出好的分類模型。
其他常見的 Undersampling 技巧
在 SMOTE 演算法中,我們知道 k-nearest Neighbors 對生成新樣本很有幫助,通時我們也可以利用 k-nearest Neighbors 幫我們移除陰性個體,比如說:Condensed Nearest Neighborhood Rule (請見 Wiki) 幫助我們移除離邊界很遠的陰性個體,讓我們的訓練資料可以幫助模型找出更清楚的陰陽兩隔邊界;Neighborhood Cleaning Rule 則是如果有一個陰性個體最近的三個鄰點有兩個是陽性的話,我們就將該陰性個體視為雜訊並移除之。一定要注意的是,如果在做不平衡分類時,使用了 undersampling 類的技巧,那麼一定要很仔細地做「交叉驗證」(Cross Validation) ,確保沒有移除到很重要的資訊。
在下一篇文章中,會跟大家介紹成本導向分類 (Cost-sensitive Classification) 的理論基礎,並介紹一些常見的成本導向分類演算法。有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您按讚或留言給我喔!
大鼻觀點:https://www.facebook.com/davidperspective/
之前看到這個方法還蠻有意思的
https://www.quora.com/In-classification-how-do-you-handle-an-unbalanced-training-set/answers/1144228?srid=h3G6o
想請問文中提到「如果在做不平衡分類時,使用了 undersampling 類的技巧,那麼一定要很仔細地做「交叉驗證」(Cross Validation) ,確保沒有移除到很重要的資訊。」,CV是指在訓練模型時的CV嗎