
上學期在 Harvard 修了「統計機器學習」這門課,教授在課程中介紹了許多關於機器學習理論的最新研究,其中我覺得有一篇很有意思的論文:Neural tangent kernel: Convergence and generalization in neural networks。這篇論文在數學上雖然滿困難的,但提供了非常有趣而且容易理解的觀點:非常寬的神經網路其實可以被視為經過特定特徵轉換的迴歸模型,而從該特徵轉換可以得到一種特殊的 kernel 函數,作者稱為 Neural Tangent Kernel。
泰勒展開式與一階逼近式
假設我們想要估計一個函數 $latex f(x,\boldsymbol\theta)$,其中 $latex x \in \mathbb{R}$ 是特徵向量,$latex \boldsymbol\theta$ 是待估計的參數。通常,我們會透過梯度下降法 (Gradient Descent) 極小化某個特定的損失函數 (loss function) 來估計$latex \boldsymbol\theta$,在梯度下降的一開始會指派一個隨機的初始值 $latex \boldsymbol\theta_0$。有修過微積分的朋友應該對於泰勒展開式 (Taylor Expansions) 有一點印象,我們可以將函數 $latex f(x,\boldsymbol\theta)$ 在初始值 $latex \boldsymbol\theta_0$ 做泰勒展開式,得到以下形式(其實這樣寫可能在矩陣運算上不大正確,不過比較好理解):
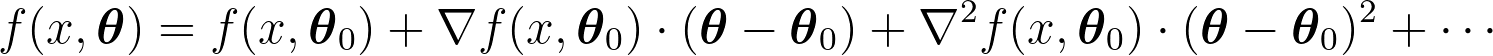 。
。
當 $latex \boldsymbol\theta$ 與 $latex \boldsymbol\theta_0$ 差異很小的時候,可以忽略平方項以上的部分,因此得到一階的逼近式:
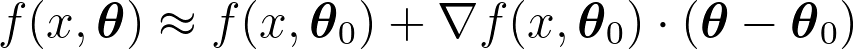 。
。
如果令 $latex \alpha = f(x,\boldsymbol\theta_0)$、$latex \boldsymbol\phi (x) =\nabla f(x,\boldsymbol\theta_0)$、$latex \boldsymbol\beta =\boldsymbol\theta – \boldsymbol\theta_0$,會發現上面的一階逼近式可以寫作 $latex f(x,\boldsymbol\theta) = \alpha + \boldsymbol\phi (x) \cdot \boldsymbol\beta$,即是基於轉換後特徵 $latex \boldsymbol\phi (x) =\nabla f(x,\boldsymbol\theta_0)$ 的線性迴歸。之所以叫做 Neural Tangent,主要是因為這個轉換其實是計算神經網路的梯度,而梯度就是垂直該神經網絡的方向。
Neural Tangent Kernel
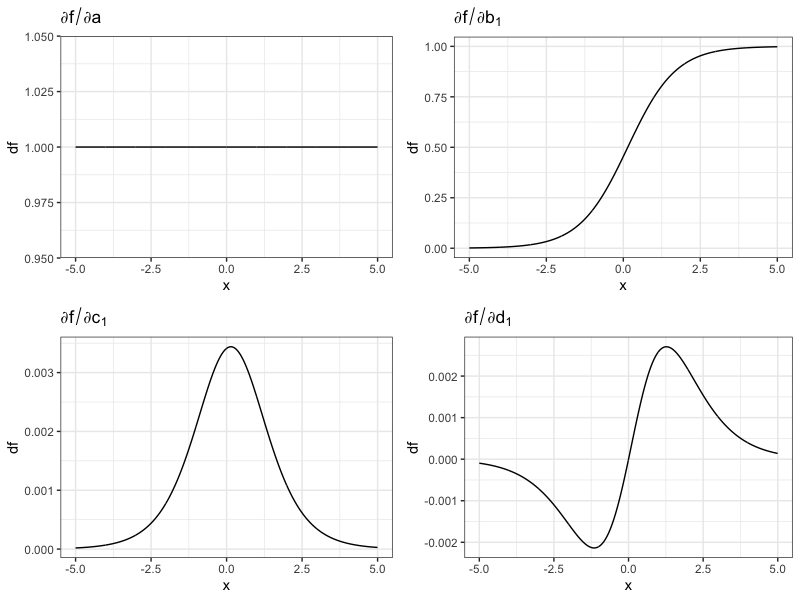
從上面得到的一階逼近式,我們可以得到神經網絡在進行訓練時做的特徵轉換。為求簡化,假設 $latex x$ 只有一維,我們想要訓練只有一層、m 個節點的神經網絡(如下圖所示),其中每一個節點都經過 $latex b_i \cdot (c_i x + d_i)$ 的轉換,如下圖所示。(註:這個例子是教授出在作業的題目,並不是我自己想的~)
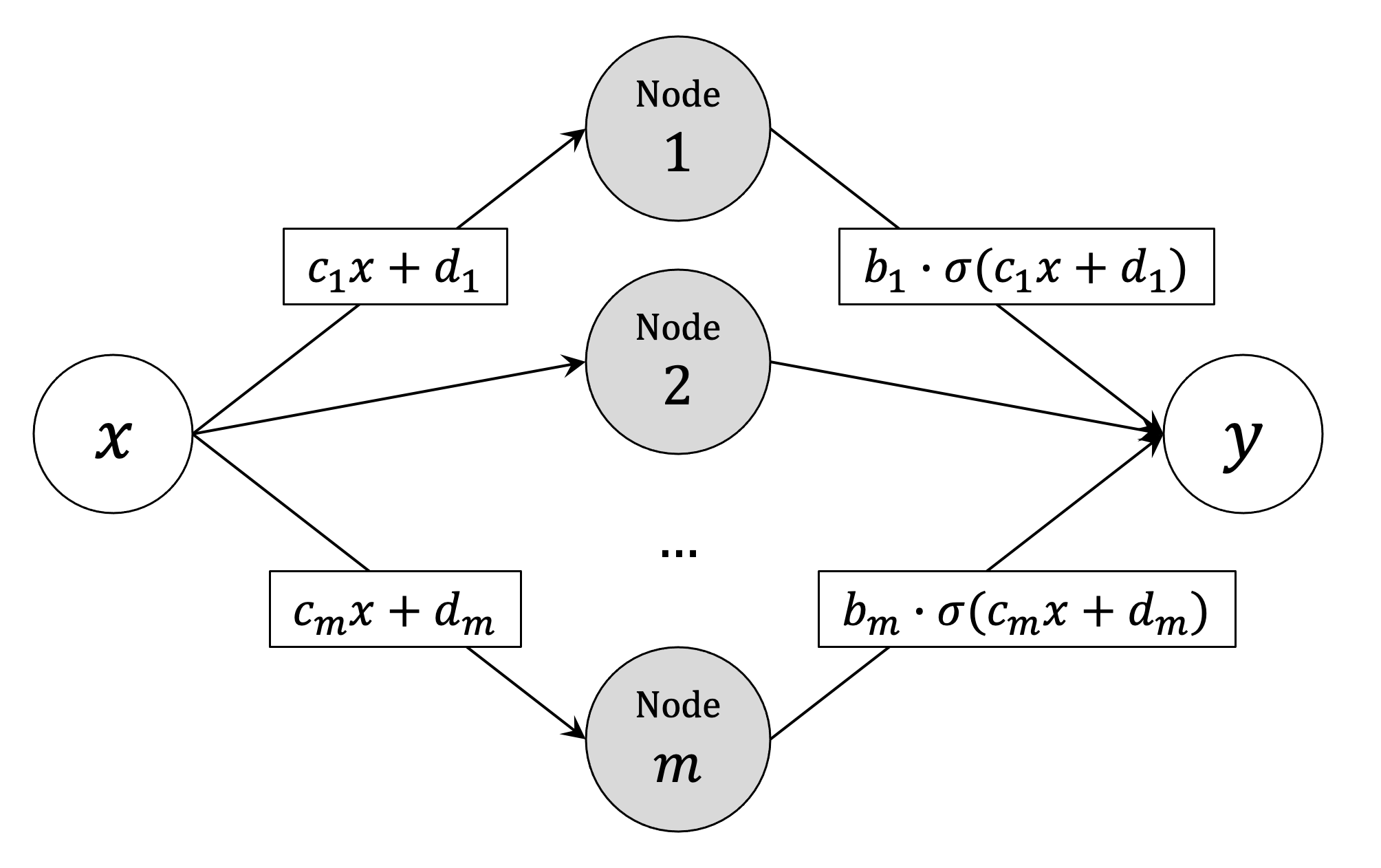
令 $latex \theta = (a, b_1, \cdots, b_m, c_1 \cdots, c_m, d_1, \cdots, d_m)\in \mathbb{R}^{3m+1}$,則上述的神經網絡可以寫作函數
$latex f(x,\boldsymbol\theta) = a + \sum_{j=1}^m b_j \cdot \sigma(c_j x + d_j)$ ,其中 $latex \sigma(z) = 1 / (1+\exp(-z))$ 為一般的乙狀函數 (sigmoid function)。此時,給定初始的 $latex \boldsymbol\theta_0$,我們可以透過簡單的微分得到該神經網絡進行的特徵轉換:
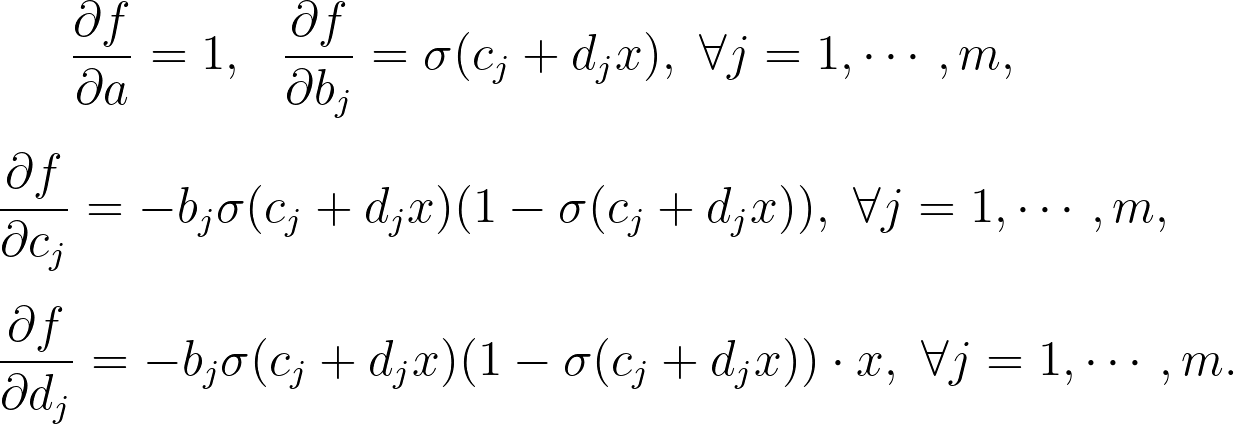
下圖是針對某一組隨機初始值得到特徵轉換的函數圖形。可以發現,只有一層、寬度為 $latex m$ 的神經網絡,其實很像是利用四種函數做線性組合:截距項、乙狀函數、鐘形曲線(局部的正向跳躍)、與 impuse-response 函數。
局部的線性逼近不一定成立
其中一個主要的問題是,線性逼近是要確保在 $latex \boldsymbol\theta$ 與 $latex \boldsymbol\theta_0$ 差異很小時,所以當我們的隨機初始值離最後收斂的估計值太遠,造成梯度下降中每一步變化很大時,上述的線性逼近並不成立,只有在 LeCun initialization 的情況下才會成立。 此外,這種方法並不能完全解釋神經網絡的行為,許多實證研究發現 Neural Tangent Kernel Regression 的表現還是不如訓練一個 over-parametrized 的神經網路。如果想要看更仔細的解釋,可以參考這篇很清楚的部落格文。
有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
這篇真的寫得很棒,原始論文真的看得很痛苦