
交叉驗證 (cross validation) 是衡量監督式學習 (supervised learning) 模型主流的模型衡量方法,原理相信大家並不陌生,以 K-fold cross validation 為例,我們會將蒐集到的資料集合分為 $latex K$ 等份的子樣本,接著用同樣的特徵、演算法與參數建立 $latex K$ 個不同的模型,其中每個模型都是由其中一組子樣本當做測試集合 (test set)、另外 $latex K – 1$ 組作為訓練集合 (training set),計算出 $latex K$ 個不同的模型估計誤差,最後將這 $latex K$ 個誤差做平均,當作最後模型的衡量指標(簡稱 CV error)。K-fold Cross Validation 在 $latex K = n$ ($latex n$ 為原始資料集合的個體數)的情況叫做 LOOCV (Leave-one-out Cross Validation),也就是每次只留一個個體當做測試集合,用剩下的 $latex n-1$ 個個體當做訓練集合,計算估計誤差。
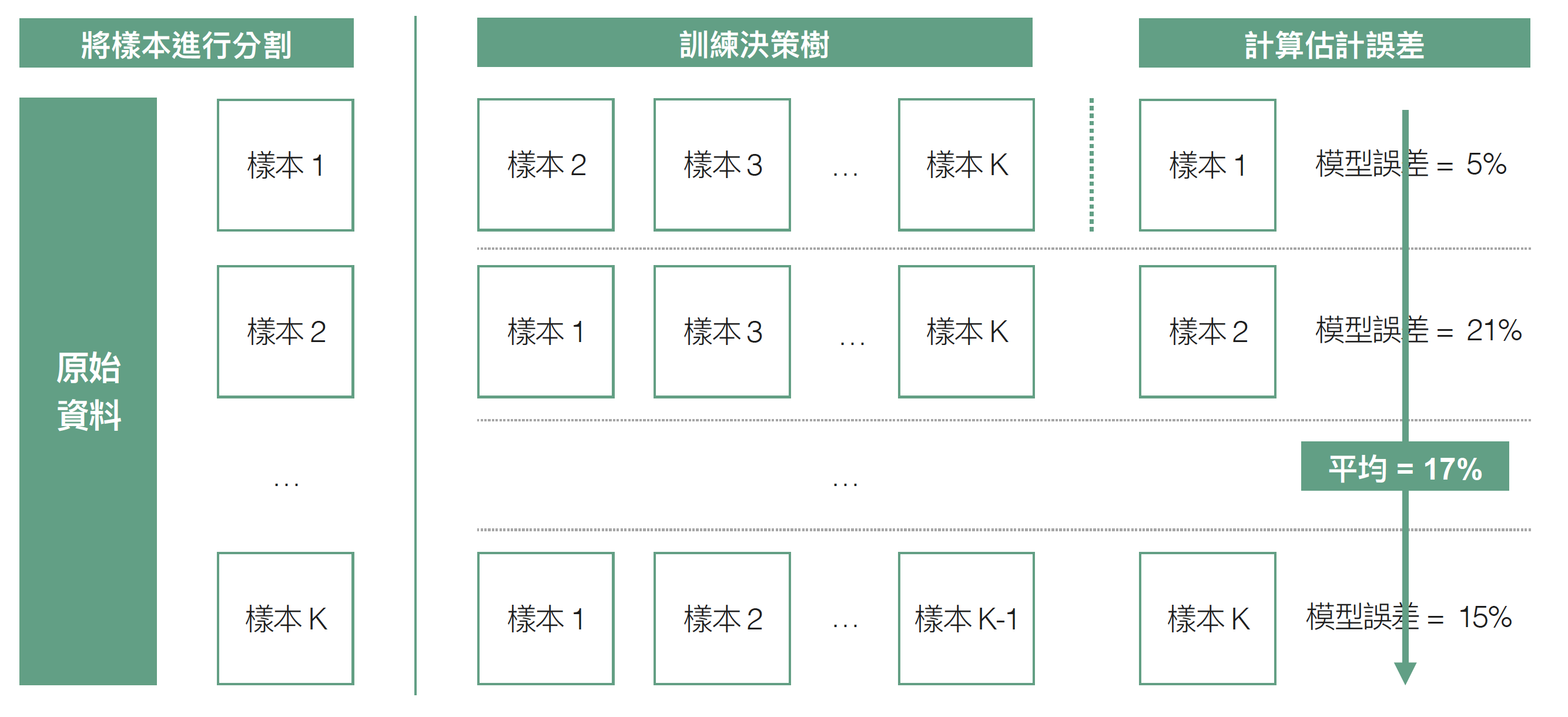
交叉驗證得到的模型誤差很常被用來作為模型選擇的依據,通常我們會比較兩組不同演算法的 CV error,選擇 CV error 較低的演算法當做最佳的模型。這時自然而然會冒出一個統計推論的問題:在目前蒐集到的資料集合上演算法的 CV error 比較低,就代表真正的 test error 就會比較低嗎?會不會只是剛好在目前蒐集到的資料集合上發生的巧合呢?傳統統計學遇到這類問題,我們直覺反應就是透過「假設檢定」(hypothesis testing) 來控制型一錯誤 (Type I error),確保我們聲稱 「演算法 1 的 test error 比較低」具有「統計顯著性」。因此,今天想要來跟大家介紹這篇論文 Cross-validation Confidence Intervals for Test Error,提供 cross validation 估計 test error 的信賴區間與假設檢定的理論架構。
CV Error 與 Test Error 的定義
假設我們觀察個體產生的資料點為 $latex \{Z_i\}_{i\geq 1}$,以監督式學習為例,$latex Z_i = (\mathbf{X}_i,Y_i)$ 代表第 $latex i$ 個個體觀察到的特徵 (feature) 與結果 (outcome),通常一組有 $latex n$ 個觀察個體的資料集合可以紀錄為 $latex Z_{1:n}$。令 $latex B$ 代表從 $latex \{1,2,\cdots,n\}$ 選出一些元素最為一個向量(比如說:$latex B = (1,3,5,n)$),則 $latex Z_B$ 就是從資料集合 $latex Z_{1:n}$ 抽樣出的一個子樣本。所以,我們可以將訓練與驗證集合的分割 (training-validation split) 表示成 $latex (B,B’)$,其中 $latex B \cup B’ = \{1,\cdots,n\}, B \cap B’ = \phi$。因此, K-fold cross validation 就可以表示成 $latex \{(B_j, B’_j)\}_{j=1}^K$,其中 $latex (B_j, B’_j)$ 都是一組 training-validation split,而 $latex B’_1, \cdots, B’_K$ 可以均等的將 $latex \{1,2,\cdots,n\}$ 分成 $latex K$ 等份。
給定損失函數 (loss function) $latex h_n(Z_i, Z_{B})$(每一個個體的估計誤差除了與 $latex Z_i$ 本身有關外,也會因不同訓練集合 $latex Z_{B}$ 訓練出不同的模型而有所差異),比如說:迴歸問題的損失函數通常是 $latex h_n(Z_i, Z_{B}) = (Y_i – \widehat{f}(X_i; Z_{B}))^2$,其中 $latex \widehat{f}(X_i; Z_{B})$ 代表利用 $latex Z_{B}$ 訓練出的機器學習模型,而分類問題的損失函數通常是 $latex h_n(Z_i, Z_{B}) =\mathbf{1}(Y_i – \widehat{f}(X_i; Z_{B}))$。接著,我們就可以定義出 K-fold cross validation 得到的估計誤差 (CV error) 為:
![]()
也就是將每個個體在每個 fold 估計出的誤差加在一起在除上 $latex n$(當然可以再除上 $latex K$ 做標準化)。而我們真正想估計的 test error 為:
![]()
CV Error 的中央極限定理
在思考 CV error 與 test error 的誤差時,需要思考 CV error 的變異數。為求推導方便,我們先把「誤差變異」的重心放在 K-fold 中的其中一個 fold,比如說:放在訓練集合由個體 $latex 1, 2, \cdots, n – n/k$ 組成,記為 $latex Z_{1:n(1-1/k)}$ 的 fold。此時,利用這組訓練集合得到的模型,其單一個體的期望損失函數可以寫成 $latex \overline{h}_n(z) = \mathbb{E}[h_n(z;Z_{1:n(1-1/k)})]$,此處期望值的變異來源是來自 $latex Z_{1:n(1-1/k)})$。其變異數可以紀錄為 $latex \sigma_n^2 = Var(\overline{h}_n(z))$。
接下來,這篇論文證明出了「中央極限定理」(Central Limit Theorem):假設 $latex Z_i$ 是母體分配(以隨機變數 $latex Z_0$ 表示)的一組隨機樣本(也就是個體間彼此獨立且分配相等),則在一些寬鬆的條件下,我們可以得到中央極限定理:$latex \frac{\sqrt{n}}{\sigma_n}(\widehat{R}_n-R_n) \rightarrow_{d} \mathcal{N}(0,1)$,其中 $latex \sigma_n^2 = Var(\overline{h}_n(Z_0))$。所以,下一個問題就是:要怎麼樣估計 CV error 的變異數 $latex \sigma_n^2$?
CV Error 的變異數估計
如果要確保中央極限定理仍然運作,我們的目標是找到 $latex \sigma_n^2$ 得一致估計式 (consistent estimator) $latex \widehat{\sigma}_n^2$。在論文中得出了兩種類型的一致估計式,第一種是針對 K-fold cross validation 的估計式:
![]()
該估計式在論文被稱作 within-fold variance estimator,也就是「在每一個 fold 的測試集合上計算 $latex h_n(Z_i,Z_{B_j}$ 的變異數,在把 $latex K$ 個 fold 得到的變異數做平均」。但是這樣的估計式,沒有辦法套用在 LOOCV 上(因為測試集合都只有 1 個個體),所以論文也提出了另一個估計式:
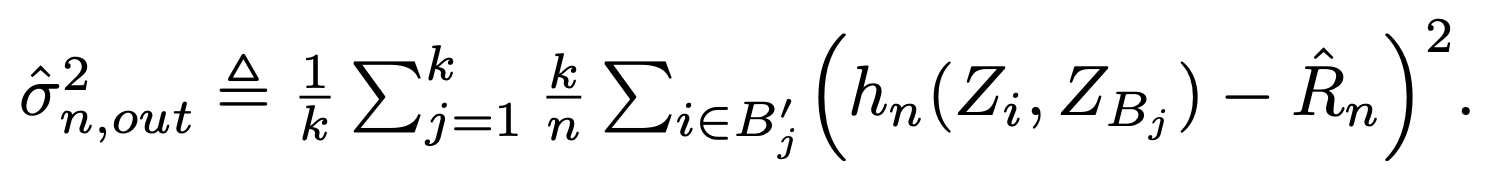
該估計式則是被稱作 all-pairs variance estimator,主要是因為該估計式直接將「利用所有 LOOCV 得到的估計誤差值計算變異數」。
CV Error 的信賴區間與假設檢定
有了一致估計式,我們就可以利用分配收斂的性質得到以下的重要性質:
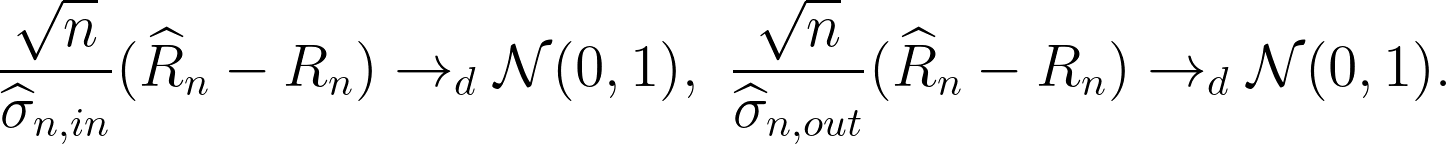
因此不論你使用的是 within-fold variance estimator 還是 all-pairs variance estimator,在樣本數 $latex n$ 很大的時候,可以得到 test error 的 95% 漸近信賴區間為 $latex \widehat{R}_n\pm 1.96 \cdot \widehat{\sigma}_n / \sqrt{n}$。
另外,我們想在給定資料集合 $latex Z_{1:n}$、K-fold 的分割 $latex \{B_j, B’_j\}_{j=1}^K$ 下,檢定兩個演算法 $latex \mathcal{A}_1$ 是否比 $latex \mathcal{A}_2$ 表現得更好,這時可以將原本的 $latex h_n$ 函數定義為:
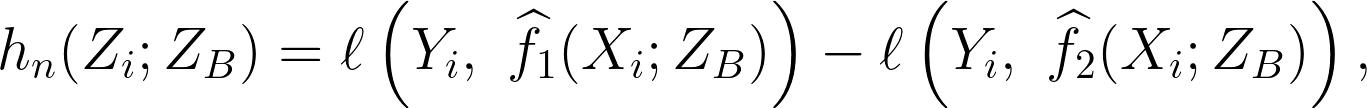
其中 $latex \ell$ 是本來用來計算誤差的方式,比如說: $latex \ell (Y_i, \widehat{f}_1(X_i; Z_{B})) = [Y_i, \widehat{f}_1(X_i; Z_{B})]^2$,而 $latex \widehat{f}_1(X_i; Z_{B})$ 則是 $latex \mathcal{A}_1$ 在訓練集合 $latex Z_B$ 上訓練出的模型。這時,上述得檢定問題就變成: $latex H_0:~R_n \geq 0~~v.s. ~~H_1:~R_n < 0$,如果拒絕虛無假設就代表 $latex \mathcal{A}_1$ 的誤差比較小,表現較佳。在顯著水準 $latex \alpha$ 下,虛無假設的拒絕條件就是 $latex \widehat{R}_n < q_{\alpha} \cdot \widehat{\sigma}_n / \sqrt{n}$,其中 $latex q_{\alpha}$ 是標準常態分配的 $latex \alpha$-quantile。
小結:這篇文章的優點
其實估計 test error 的信賴區間之前有很多論文有討論過,但這篇論文得到的結果最大的好處是— (1) 不需要假設 CV error 之間是獨立的(因為信練集合的重複性,所以其實每一個 fold 計算出來的訓練誤差其實是相關的),(2) 不需要什麼重複抽樣的技巧就可以估計出變異數,降低計算成本。當然,這些定理的成立其實有針對穩定性 (stability) 做一些假設,所以這是實務上要再去了解到底穩定性假設在一般的資料集合上會不會成立。
有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
大鼻觀點:https://www.facebook.com/davidperspective/