

在前一篇文章中,我們介紹了 InfoQ 架構與系統性思考資訊品質的方法,接下來的文章會要跟大家分享 InfoQ 的八大面向,並分享我自己的實務經驗中的體悟,當然提到的都是虛構個案。如果想要更了解 InfoQ 的八大面向,可以閱讀這一篇很實用的論文:Kenett, R. S., & Shmueli, G. (2016). From quality to information quality in official statistics. Journal of Official Statistics, 32(4), 867-885.
回顧「資料分析的 pipeline」,一個完整的資料分析專案通常包括了三個階段:
- 資料蒐集:通常 90% 的專案時間其實是在「定義問題」與「蒐集資料」階段
- 資料分析:考驗資料科學家硬底子功夫的階段,同時也考驗資料科學家能不能有創意的設計模型
- 資料輸出:當你越有「使用者經驗設計」、「商業領域知識」、「資料工程」,你越能在這個階段達成目標
每個階段,其實都有對應的幾個衡量面向。在資料蒐集階段,我們需要評估「資料解析度」(Data Resolution)、「資料架構」(Data Structure)、以及「資料整合」(Data Integration) 三個面向;在資料分析階段,需要評估「時間攸關性」(Temporal Relevance)、「資料與目標的時序關係」(Chronology of Data and Goal)、以及「推廣能力」(Generalizability);在資料呈現階段,需要評估「作業化/生產化」(Operationalization) 與「溝通」(Communication)。
在這篇文章,我會以 A/B 測試為主軸,解釋資料蒐集階段的三個 InfoQ 面向:「資料解析度」(Data Resolution)、「資料架構」(Data Structure)、以及「資料整合」(Data Integration) 。在解釋概念的同時,也會簡單分享我過去工作中的經驗,也期待有朋友可以分享自身的經驗!
「資料解析度」(Data Resolution)
資料解析度指的是資料的「量測尺度」(Measurement Scale) 與「加總層級」(Aggregation Level):
- 「量測尺度」指的是資料蒐集個體的等級,比如說:是要比較「兩種個體」的不同,還是比較「兩種市場」的不同。
- 「加總層級」則是指要不要把變數加總在一起看,比如說:要看家戶的總所得,還是要看家戶的工作所得、投資所得、其他所得三個變項。
在 A/B 測試中,能否隨機將「相似且不會互相影響」(identical and individual) 的使用者分成實驗組與對照組,也就是能否取得統計理論中的「隨機樣本」(random sample)。如果不能,我們就需要仔細思考「量測尺度」:在什麼樣的尺度下能夠得到相較之下較為隨機的樣本。
假設你是訂房網站的資料科學家,產品團隊希望「提升房客人數來增加旅館收入」,因此設計了新的旅館廣告 UI 頁面,請你幫助他們衡量新的設計能夠為旅館帶來多少的收入。如果只是隨機將使用者分配到不同網站,這時最大的困難就是:會不會新設計旅館 (測試組) 新賺來的錢是因為搶食 (cannibalize) 舊設計旅館 (對照組) 的客人,當所有旅館的廣告頁面變成一樣時,其實是沒有辦法增加消費者訂房的意願使旅館收入增加。當測試組會影響對照組個體行為時,我們很難衡量新設計真正帶來的效益。此時,我們會建議挑選「相似的市場」做測試,比如說:選擇多個使用者與房東有類似行為的行政區做測試,比較測行政區與採納就設計的。
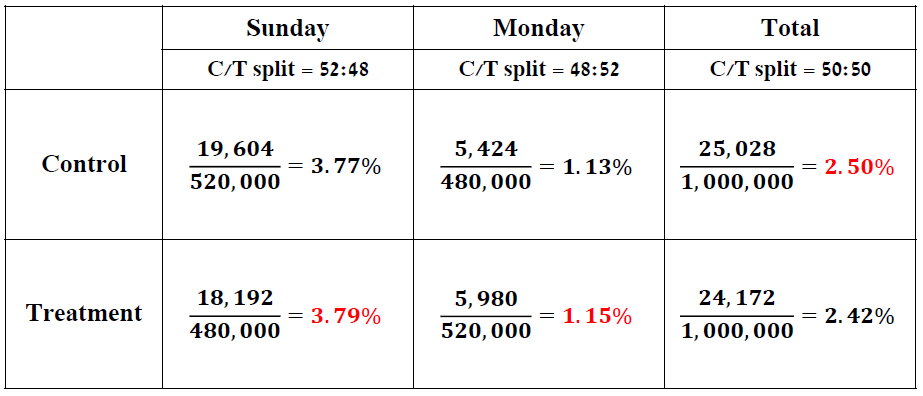
在「加總層級」部分,最需要小心的就是「辛普森悖論」(Simpson’s Paradox)。我們可以從以下例子來看:假設我們蒐集了兩天的實驗資料,蒐集了總共 200 萬個使用者,其中 100 萬個使用者是實驗組 (Treatment Group),另外 100 萬個使用者是控制組 (Control Group),計算出來發現點擊率 (Click-through Rate),結果是控制組表現較佳。然而,我們拆解成禮拜天跟禮拜一的結果,發現這兩天單獨看都是實驗組比較好!會有這樣的原因主要是:(1) 星期天跟星期一的 CTR 差很大 (2) 星期天跟星期一實驗組 / 對照組的比率並不是 1:1。因此,「加總」是要謹慎評估的─在蒐集資料前,就要特別確保蒐集到的變數是不是真正可加的,如果星期日跟星期一實驗組 / 對照組的比率是一樣的,就不會出現下面的問題。
「資料架構」(Data Structure)
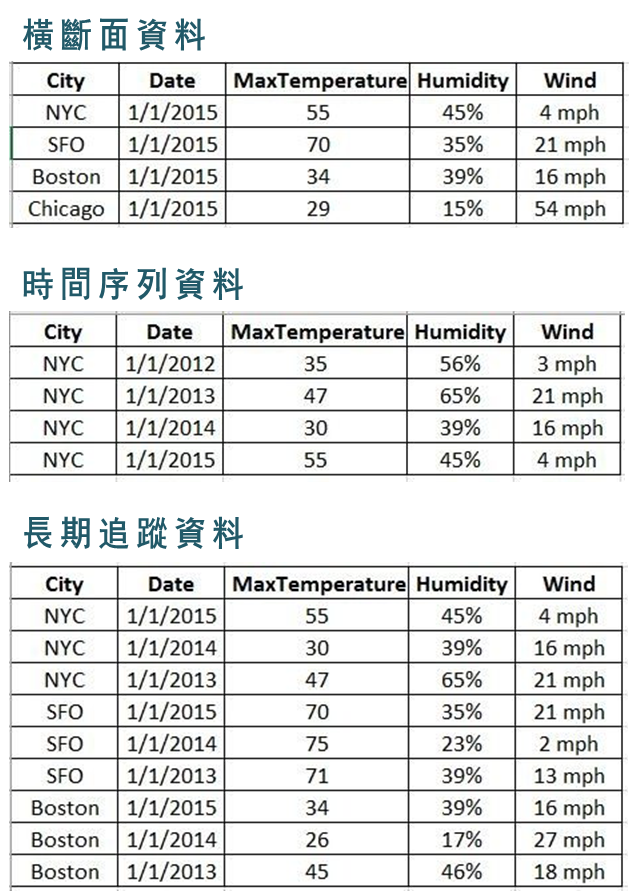
資料架構與資料的特性與蒐集方法有關,一般常見的結構化資料有三種型式:橫斷面資料 (cross-sectional data )、時間序列資料 (time series data)、以及長期追蹤資料 (longitudinal data),其中的差別在:
- 橫斷面資料 (cross-sectional data):每個個體 (observations) 在單一時間點的行為 (behaviors) 。
- 時間序列資料 (time series data):單一個體在多個時間點的行為。
- 長期追蹤資料 (longitudinal data):每個個體在多個時間點的行為。
下列是來自 Quora 上的範例,很清楚的解釋三種不同資料的架構。
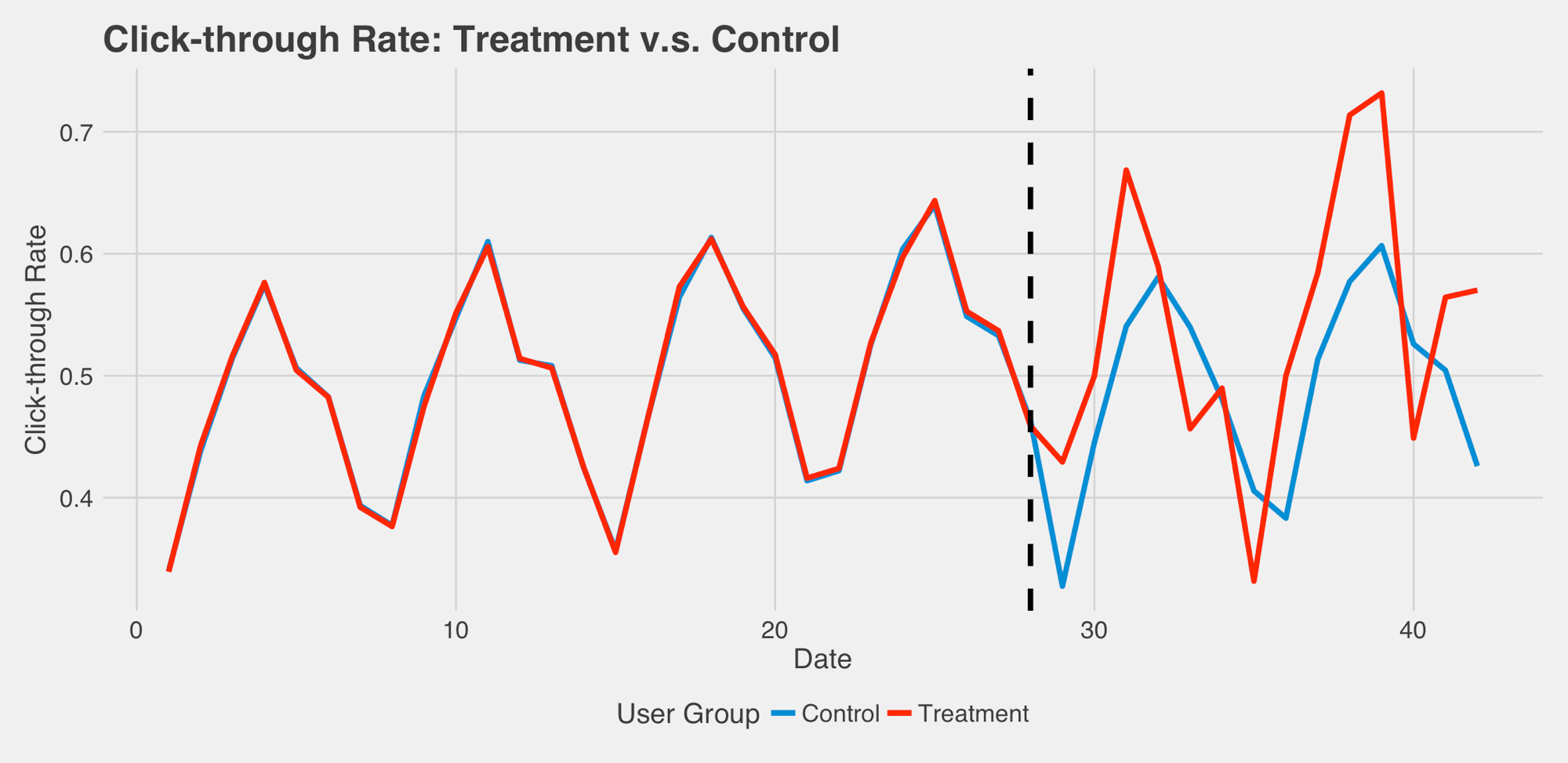
在 A/B 測試中,我們時常將蒐集到的資料當作橫斷面資料,但如果遇到以下情況,可能就有一點頭大了:雖然實驗組的點擊率 (Click-through rate) 看起來比對照組好 (虛線代表實驗開始時間),但好像忽好忽壞,變異較大,這樣的結果到底是不是代表實驗組比較好呢?
這時,我們可以將實驗組與對照組的目標變數相減得到差值,以及計算累計差值,繪製成下列圖形,可以很容易看出實驗後的差異。如果震盪沒有像下圖一樣明顯,可以做時間序列的結構變化 (structural break) 檢定,確定在實驗開始前後兩組差值有顯著變化。
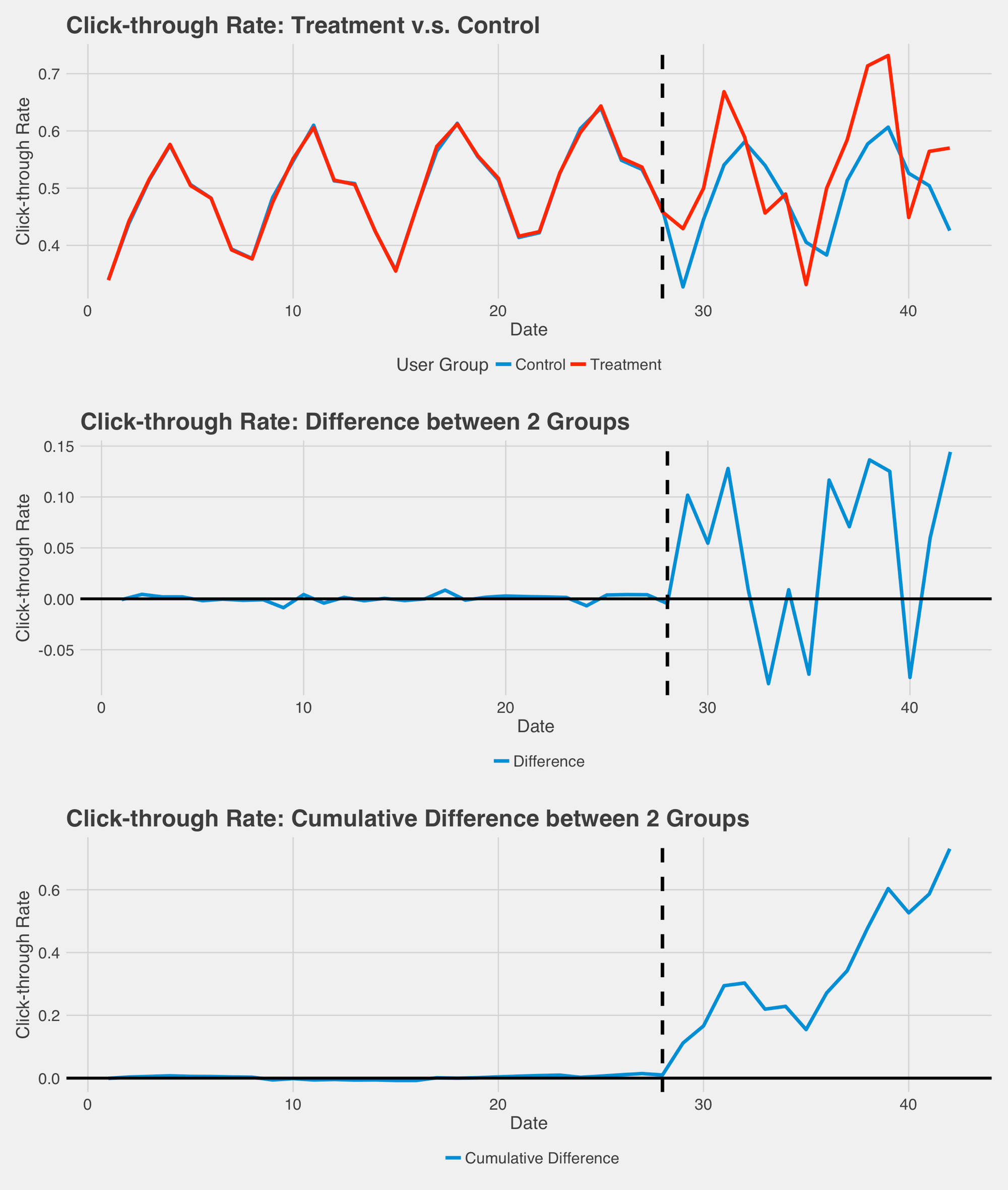
從上圖仍然有點難量化衡量實驗對於使用者的影響,這時我們可以用迴歸模型,或是時間序列拆解 (time series decomposition),去比較實驗組與控制組之間在長期趨勢上的不同。
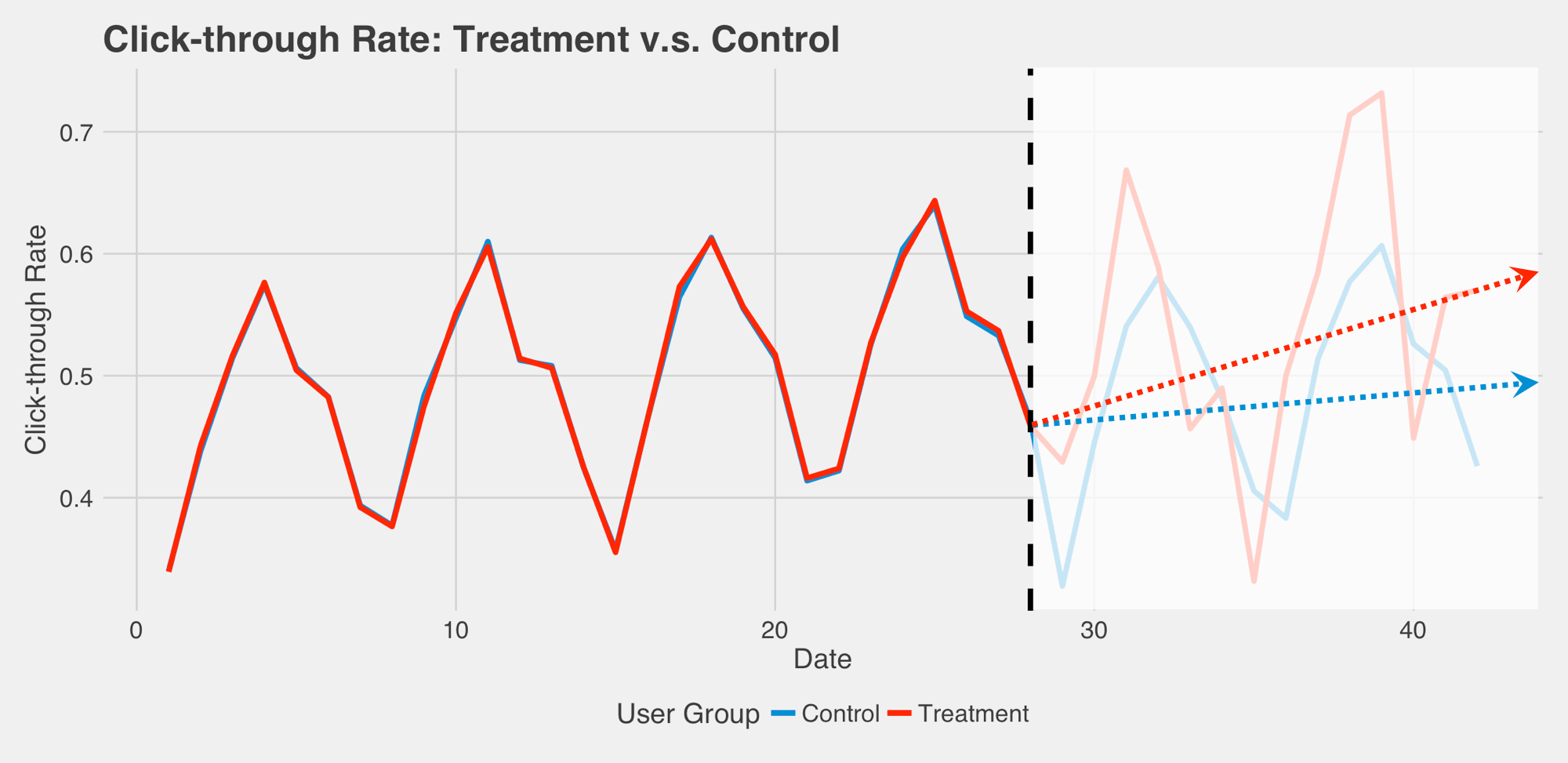
從上述的案例可以知道,資料蒐集的形態不一樣,我們會選擇的分析方法也就不一樣。選擇太過簡單的方法,可能會損失太多重要資訊,得到過於模糊的結果;反之,選擇太過複雜的模型,可能會過度捕捉雜訊,無法抓出資料真正的模式。因此,在蒐集時就先確認好需要的資料結構,並預想可能的蒐集方法,將能改善分析專案的 InfoQ。
「資料整合」(Data Integration)
大部分資料分析專案的資料都來自許多不同的資料源,每個資料源會得到的變數型態也不盡相同,整併包含不同資訊的資料源常會有利於我們看到更多洞見,但也可能會讓資料變得一團混亂。因此,在進行資料整合時,要注意:
- 每個資料源蒐集資料的方式是什麼?蒐集的方式可靠嗎?什麼情境下資料源會變得不可靠?
- 不同資料源整合在一起的連結方式是什麼?會有像是關聯式資料庫的主 key 可以連結嗎?
- 資料整併後能夠幫助我們達成分析目標嗎?我們能夠解釋整併後的數據意義嗎?
- 資料整合會不會產生隱私問題?會不會可以辨認出去識別化資料中的個體是誰?
在 A/B 測試中,資料整合其實是至關重要的。比如說,在做使用者抽樣時,我們要怎麼確認使用者足夠有代表性呢?通常我們會希望「被抽樣的使用者」跟「目標研究的母體」在重要的特徵上是相近的,比如說:連續劇 App 公司會希望抽樣出來的樣本在觀看時間與使用 App 頻率是一樣的;搜尋引擎公司則會希望實驗對象不是「爬蟲」,所以希望實驗對象的搜尋次數在某個區間之內;如果是網路行銷公司,可能會希望使用者的年齡、收入等特徵跟該測試市場人口的分布類似。從上述的案例中,可以知道光「實驗個體抽樣」就會需要整合不同類型的資料。
此外,我們在計算 A/B 測試的指標時,也會需要整合很多不同的資料源,Airbnb 的 A/B 測試架構是很棒的案例,在做 A/B 測試時會有以下幾個步驟的整合:
- 將分組指派資料與事件資料進行合併
- 根據個體進行事件資料的彙總
- 將上述資料根據不同實驗進行彙總
- 將上述資料與實驗個體特徵進行整合
- 根據實驗個體特徵進行彙總
從上述的流程可以知道,我們會透過不斷整合新資料來提高實驗的清晰度,提升資訊品質,資料整併的 ER Diagram 如下圖所示 (來自 Airbnb 的部落格)。

小結:從資料蒐集階段開始 InfoQ 分析
相信從上述例子,大家應該比較可以理解 InfoQ 在資料蒐集階段的三個重要面向,其實不只有 A/B 測試,在所有資料分析專案的事前規劃中,都可以仔細思考這些面向,提升 InfoQ 進而提升商業決策的品質。在下一篇文章,我會進入資料分析階段,討論「時間攸關性」(Temporal Relevance)、「資料與目標的時序關係」(Chronology of Data and Goal)、以及「推廣能力」(Generalizability),可能會用推薦系統為主軸介紹上述的四個面向。
有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
大鼻你好~想跟你請教,此篇文中的資料視覺化工具是什麼呢?不確定是不是使用 R 來進行分析並用 ggplot2 來視覺化~