

從2016年初開始,大鼻一直遇到一些文字探勘的小專案,身為一個統計人,一開始當然對文字的處理很不熟悉,但隨著經驗越來越多,好像可以開始產出一些實(簡)用(單)的小文章,跟大家分享一系列文件探勘分析時常用的手法。由於之前做過的專案,最終都與機器學習有關,將文件 (document) 視為一個個體 (individual) 進行預測,所以在最開始要跟大家聊聊如何將一個文件轉換成向量表達式 (vector representation),之後才能夠繼續進行機器學習。
BoW (Bag of Words) 與詞彙數量-文件矩陣
假設現在有 $latex D$ 篇文件 (document),而所有文件中總共使用了 $latex ~T~$ 個詞彙 (term),我們就可以將文章轉換成以下類型的矩陣,其中第一欄第一列的「12」代表的是「文件 1」 中出現了12個「文字 1」。如此一來,我們可以用 $latex [12,~0,~3,~\cdots,~2]$ 這個向量來代表「文件 1」,同理也可用「文件 D」也可以用 $latex [0,~2,~8,~\cdots,~0]$ 來表示。

這樣的方法就是「BoW (Bag of Word)演算法」,這種方法雖然很簡單,但有2個主要的問題 ─ 一是每篇文章的總字數不一樣,比如說文字 2在文件 2中出現9次,在文件 D中卻只出現2次,這樣是否代表文字 2 對文件 2 比較重要,對文件 D 比較不重要呢?答案是否定的,說不定文件2有10000個字,而文件D只有50個字,如此一來文字2應該對文件D比較重要才對。
另一個問題是,時常重複出現的慣用詞彙對一個文件的影響很大。比如說,上圖中的文字 3在每個文件中都出現好多次,可能是「the」之類的常用字,如此一來「文件 D」的向量就會被 the 這個字所主導,但 the 這個字其實沒什麼特別的意義。
為了處理以上兩個問題,歷史悠久但非常好用的 TF-IDF演算法就被發明出來了。
TF-IDF 演算法
TF-IDF 演算法包含了兩個部分:詞頻(term frequency,TF)跟逆向文件頻率(inverse document frequency,IDF)。詞頻指的是某一個給定的詞語在該文件中出現的頻率,第 $latex t$個詞出現在第 $latex ~d~$ 篇文件的頻率記做 $latex ~tf_{t,d}~$,舉例來說,如果文件 1 總共有100個字,而第 1 個字在文件 1 出現的次數是12次,因此$latex ~tf_{1,1}=12/100~$,如此一來,我們就可以針對上述的第一個問題進行修正,以頻率而不是次數來看待文字的重要性,讓文章與文章之間比較有可比較性。
而逆向文件頻率則是用來處理常用字的問題。假設詞彙 $latex t$ 總共在 $latex d_t$ 篇文章中出現過,則詞彙 $latex t$ 的 IDF 定義成 $latex ~idf_t = \log\left(\frac{D}{d_t}\right)~$。比如說,假設文字 1 總共出現在 25 篇不同的文件,則 $latex ~~idf_1 = \log\left(\frac{D}{25}\right)~~$。如果詞彙 $latex t$在非常多篇文章中都出現過,就代表 $latex ~d_t~$ 很大,此時$latex ~idf_t~$ 就會比較小。
而一個字對於一篇文件重要性的分數 (score) 就可以透過TF與IDF兩個指標計算出來,我們將第 $latex t$個詞彙對於第 $latex ~d~$ 篇文件的TF-IDF權重定義為 $latex ~w_{t,d} = tf_{t,d} \times idf_t ~$。如此一來,當詞彙 $latex ~t~$ 很常出現在文件 $latex ~d~$ 時,他的 $latex ~tf_{t,d} ~$ 就會比較大,而如果詞彙$latex ~~t$ 也很少出現在其他篇文章,則 $latex ~idf_t~$ 也會比較大,使 $latex ~w_{t,d}~$整體來說比較大,也就是說詞彙$latex ~t~$ 對於文件 $latex ~d~$ 來說是很重要的。如此一來,我們就可以計算出 TF-IDF 矩陣,如下圖所示。
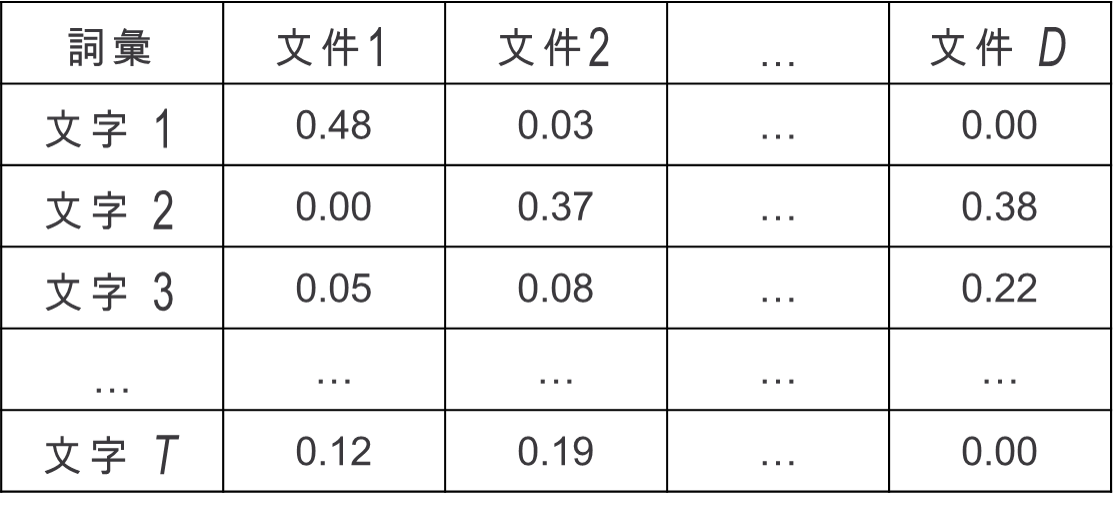
另一方面, TF-IDF 時常被用來作資訊檢索 (information retrieval),比如說,給定一串指令 (query)「文字 1 + 文字 3 + 不在現有詞彙裡面的文字」,則這串指令跟第 $latex d$ 的關聯分數就可以定義文 $latex tf_{1,d} + tf_{3,d} $。
大鼻是怎麼用 TF-IDF?
TF-IDF 常被我用在3個地方,一個是作為 baseline model的特徵 (feature),比如說作文件分類 (text classification) 時,我就會把 tf 跟 idf 都當作文件的特徵(所以一篇文章總夠會有 $latex 2T$個特徵),去跑分類模型,作為 baseline。有時候我會把一個詞彙對於每篇的文章的 tf-idf 值當作該詞彙的特徵,去跑文字的分群。還有一個是大鼻好友ㄐㄓ告訴我的妙招,就是如果我們想要用word2vec得出來的詞向量去表示一個文件的話,可以用tf-idf的值當作權重,再把該文件中每個詞向量用tf-idf當作權重加起來,效果也很不錯喔!
以上就是TF-IDF的簡介啦!希望你會喜歡這篇文章,實作其實網路上到處都有code,所以也沒什麼好實作的XD (其實這應該可以當成程設作業 lol) 希望有機會,我可以寫出word2vec的介紹給大家~
有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
1 Comment