

前情題要 ─ 資料專案的完整流程 1:Information-in
一個大型的資料分析專案,常常會需要不同的人參與,從領域專家、專業的資料分析師與資料科學家、到資料工程師或市場調查研究員等共同參與。這些人員將在整個資料分析的專案流程中扮演不同角色。一般來說,資料分析時會有三個流程:「Info-in → Info-process → Info-out」,這個過程便是台大商學研究社 BizPro 教導的核心分析流程。其中「Info-in」代表著資料蒐集的過程,「Info-process」代表著資料處理與建模的過程,「Info-out」則需要有效率且有效果的把建模結果呈現給有決策權的人,並說服他們「資料分析是有價值的」,這樣我們才不會失業!
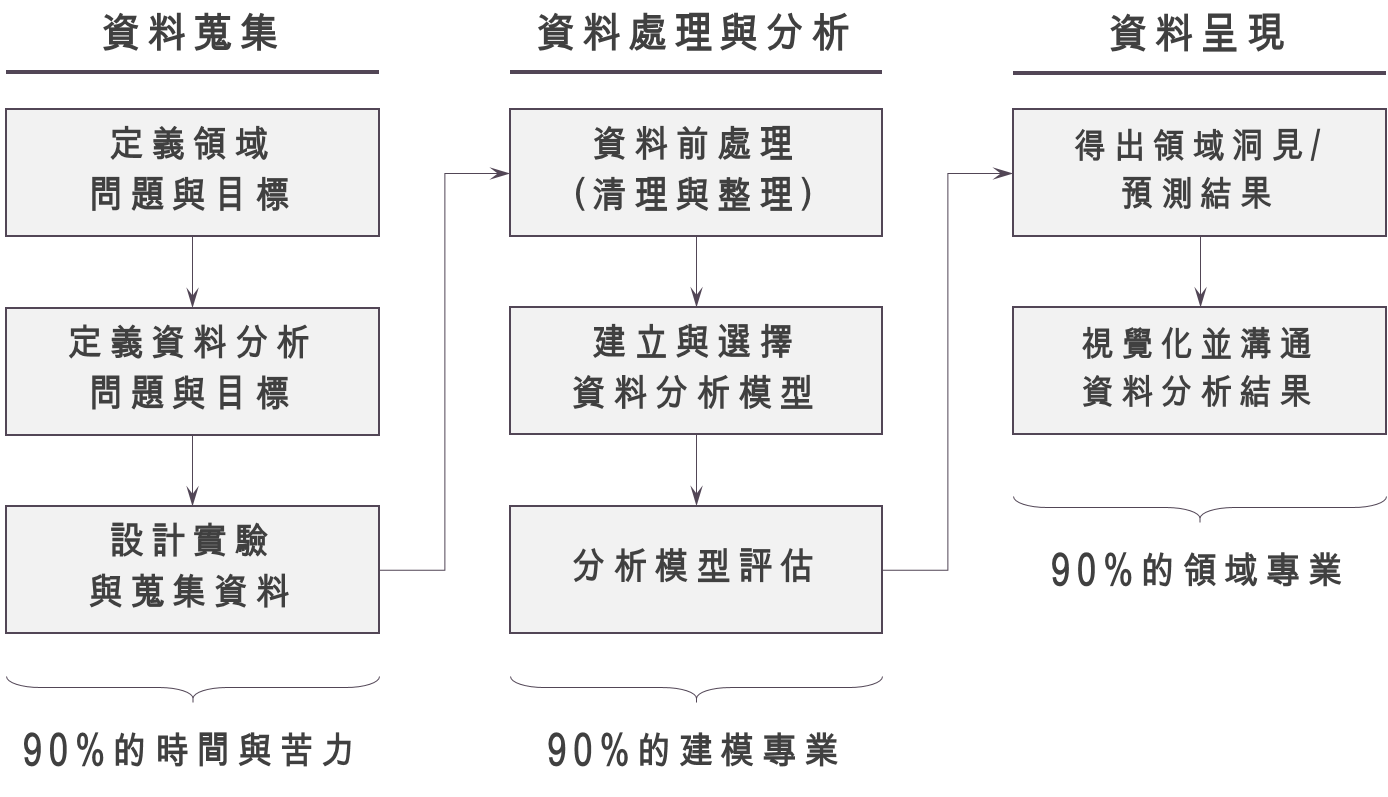
本篇文章主要討論的是整個分析流程的第二個部分─「Information-process」,這個階段就是資料科學家大顯身手的時候啦!當資料已經蒐集完整,或是資料庫的建置已經相當完備時,資料科學家會著手進行建模與分析,然而在真正進行建模前,需要進行資料的前置處理,我們叫做「資料清理」 (data cleaning) 。同時清理完畢的資料,我們也要找出比較重要的「變數」, 稱作「特徵萃取」 (feature extraction) ,「特徵萃取」也是資料分析中相當重要的步驟,從解釋的角度來看,好的特徵將能夠幫助我們正確的辨認因果關係,驗證自己的假說,從預測的角度來看,好的特徵往往能大幅提升模型的準確度 (accuracy) ,如果是需要定期執行的分析專案,會很需要一個比較好的架構,能夠不斷從資料中提取特徵,這是在所謂的重複執行資料分析 (reproducible data analysis) 中需要特別注意的。
萃取完特徵後,我們便可以開始建立模型,在 Info-in 時資料科學家心中應該已經有個譜,大致上想好後續要怎麼樣建模,因此這一步算是整個資料分析中比較輕鬆的部分。常常就是「把資料塞進去→調整參數→看結果」的過程不斷循環,當然不同類型的資料會需要用到不同的統計或機器學習技法,這是建模過程中較為困難的地方。建立好很多不同的模型後,我們要開始選擇最好的模型。資料科學家在建立模型時,絕對不會只建立一種模型,這是為什麼呢?一來是我們可能會不放心自己設計的模型是不是正確的,所以會比較不同模型的結果,看看是不是相差很多,二來不同的資料可能會適合不同的模型,這件事情在進行「分群」的時候特別容易發生。另外,在評估時我們可能會把資料完全隨機切分成很多個區塊,看看每一個區塊使用相同的模型,結果是不是差不多,以確保建立的模型是穩健的 (robust)。
大有學問的缺失資料 (missing data)
缺失值 (missing value) 是在資料前處理中相當棘手、但必然會遇到的問題,不論是從問卷調查到產品使用者資料,都可能因為蒐集資料的機器或程式有誤,問卷調查人員的疏失,甚至是使用者本身拒絕回答問題或不小心遺漏,這些因素都可能造成「缺失值」的產生。統計學家非常著重缺失資料產生的「機制」,根據不同的產生機制也有不同的處理方法,常見的缺失值機制有三種:
- 完全隨機缺失 (missing completely at random):代表缺失值的產生是完全隨機的,與任何變數都無關。比如說:問卷的受試者「不小心」沒看到薪資這個問題,因此沒有作答,則「薪資」所發生的缺失值是完全隨機缺失。
$latex ~~$ - 隨機缺失 (missing at random):代表缺失值的產生與缺失值發生的變數無關,但與其他變數有關。比如說:男性受試者通常比較不願意回答「挫折程度」相關的問題,此時「挫折程度」的缺失是建立在「性別」上的隨依缺失。
$latex ~~$ - 非隨機缺失 (missing not at random):代表缺失值的產生與缺失值發生的變數有關。比如說:高所得的問卷受試者因擔心人生安全而拒絕透漏其薪資,此時「薪資」是否缺失跟「薪資本身的高低有關」,是非隨機缺失。
$latex ~~$
為什麼我們會在乎缺失值產生的機制呢?主要原因是,時常我們因為樣本數不夠多,或是有缺失值的個體是重要的,因此不能隨便刪除有缺失值的個體,這時我們可能要進行適當的「插補」,才能讓分析繼續下去。如果是完全隨機缺失,我們或許用一些敘述統計量作為「插補值」填入缺失的地方即可,如果是不是完全隨機缺失,我們可能就要運用其他變數的資訊,或是有缺失值變數本身的資訊,來進行插補,通常「概似函數」 (likelihood function) 會在插補缺失值中扮演重要的角色。
特徵萃取與降維 (feature extraction and dimension reduction)
「特徵萃取」是資料科學中一個非常大的領域,指的是從現有的資料中找出重要的變數,也就是將原始資料的「訊號」 (signal) 找出來,並過濾掉「雜訊」 (noise)。比如說:通常在量化交易中,我們常常蒐集到的資料是「資產價格」,但由於價格這類型的時間序列比較難建模,我們常常會將其計算成「對數報酬率」進行建模,這樣的過程我們可以說是一種特徵萃取。另外,「特徵萃取」指的也可能是將非量化的資料轉為量化的表達式 (representation)。比如說:一篇ptt的po文,可以透過「doc2vec」轉換成一個數值的向量表達,又或是人臉辨識中我們會將一張圖片透過「蜷積神經網絡」轉換成一個特徵向量。「特徵萃取」並不一定會讓變數減少,有時候我們可能會希望把舊有的變數擴展成更多有意義的變數,比如說:將財務報表的資料進行運算,得出不同的財務比率,如此一來我們的變數在「特徵萃取」的過程中反而會增加。
另外,我們也可能會在建立模型對資料進行「降維度」 (dimension reduction) 處理,這種情況特別常被應用在基因相關的資料分析。進行檢測時,一個病人通常會紀錄上千個可能有問題的基因片段,但常常病人的數量不夠多,因此常常會造成「變數比樣本多」的情況,這時降維度分析便能派上大用。另外,降維度分析也可以幫我們化簡變數的結構,比如說:進行行銷問卷調查時,常會設計數量相當多的問題給受試者,每個題目間彼此可能會有些共同因素,若能透過「因素分析」 (factor analysis) 把共同因素都給找出來,我們就成功將變數(問題) 降維到只保留重要的共同因素。
資料分析模型建立與評估:根據目標選擇方法
在整理好資料,建立與選取好正確的特徵變數後,通常要開始進行模型建立。我將自己常用的資料分析模型分為三種,分別是「商業建模」、「統計模型」、「機器學習」,各種類型的模型有不同的運用面向。「商業建模」主要目標是透過資料分析,提出「資訊佐證」的商業決策,以EXCEL作為主要工具,建立 spreadsheet 模型,根據不同的目標,進行「市場大小估計」、「需求預測」、「評價與估值」等模型的建構,是商業分析師最常用的工具。而一般資料科學家則比較常進行「統計模型」與「機器學習」的模型建構,之前在在「解釋、個體預測、趨勢預測:資料科學的三個面向」一文中有介紹過「統計模型」非常適合用來驗證因果關係,而「機器學習」在預測的表現非常強。

建立完模型後,我們需要進行「模型評估」 (model evaluation),不同的模型有非常不同的評估方式。在「商業建模」中,我們時常要比對建模的結果與「策略分析」和「商業洞見」的結果是否一樣,也會透過多種不同資料來源與模型的相互比對,確認建模結果的「穩健性」 (robustness)。「統計模型」看重的是模型的「解釋能力」 (explanatory power) 或「配適程度」 (goodness-of-fit),也就是我們所建構的統計模型能夠解釋多少的資料變異。「機器學習」的主要衡量指標有兩類,一是「預測誤差」 (prediction value) ,二是距離 (distance metrics),當然不同類型的問題衡量指標也會相去甚遠。
下一步:資料的呈現 (Information-out)
在這篇文章,我僅用很走馬看花的方式把資料科學家的建模手法介紹一遍,一來是因為並不是每個領域我都很有經驗,所以盡量在不誤人子弟的情況下寫出我的看法,二是這整個步驟中的技巧與模型五花八門,但每一個方法與模型背後都有比較深的數學與統計原理,因此很難一次交代清楚。如果對哪個主題有興趣,大鼻可以推薦一些相關的書籍。
下一篇文章,將會介紹大鼻是如何將資料呈現給不同領域的人觀察。對大鼻來說,做資料視覺化最重要的目標有二,一是找出隱藏的資訊 (hidden information):在我們進行高維度資料分析時,我們經常會 (1) 看各個變數的分配 (2) 看因變數與果變數的關聯 (3) 看因變數與因變數之間的關聯,這時適當的視覺化 (大鼻最愛的是heatmap跟density level-curve)可以幫助我們找到一些隱藏的資訊。二是證明自己的論點:在商業世界中,我們經常要用「資料」佐證自己提出的策略與建議,這時候如何「有效果」且「有效率」地呈現數據將決定你是否能夠說服你的主管或客戶。有效果的重點在於「能否準確地呈現資料」,「有效率」的重點在於「能否讓聽眾很快速的了解你想說的話」。本系列下一篇部落格文章可能需要比較久的時間才會完成,還請多多見諒!
有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
大鼻觀點:https://www.facebook.com/davidperspective/
1 Comment