

現代資料分析已經不再是工程師或是統計學家才懂得玄學,而是一個「創造價值」的全新科學服務。因此資料科學家必須要花費大量時間跟不同背景的人溝通,像是在 CHOCOLABS 實習時,我做的資料分析報告除了要讓同個部門的同事與主管了解背後的分析方法 (methodology),內容策略部門的同事也會看這份報告。
這份報告背後其實有滿複雜的演算法跟統計模型,我的主管與部門同事會需要確認這樣的邏輯是否妥當,以及思考這些方法能不能應用在其他的問題上,但其他部門的人更在乎這些分析結果在內容策略上有那些意義跟啟發。因此,如何有效的溝通並讓關注不同議題的人都能了解分析結果是偏analytics派的資料科學家必備的技能。但我認為,「資料分析的流程」是每一個工作者都可以了解,也應該試圖去了解的重要方法論。今天要特別來分享在做資料分析專案時,我習慣的「流程」 (process) 是什麼,因為這是一個滿大的主題,所以我這將會是有三篇文章的系列文,跟大家分享我在「Info-in → Info-process → Info-out」分析流程中的經驗與想法。
Info-in → Info-process → Info-out 的分析流程
一個大型的資料分析專案,常常會需要不同的人參與,從領域專家、專業的資料分析師與資料科學家、到資料工程師或市場調查研究員等共同參與。這些人員將在整個資料分析的專案流程中扮演不同角色。一般來說,資料分析時會有三個流程:「Info-in → Info-process → Info-out」,這個過程便是台大商學研究社 BizPro 教導的核心分析流程。其中「Info-in」代表著資料蒐集的過程,「Info-process」代表著資料處理與建模的過程,「Info-out」則需要有效率且有效果的把建模結果呈現給有決策權的人,並說服他們「資料分析是有價值的」,這樣我們才不會失業!
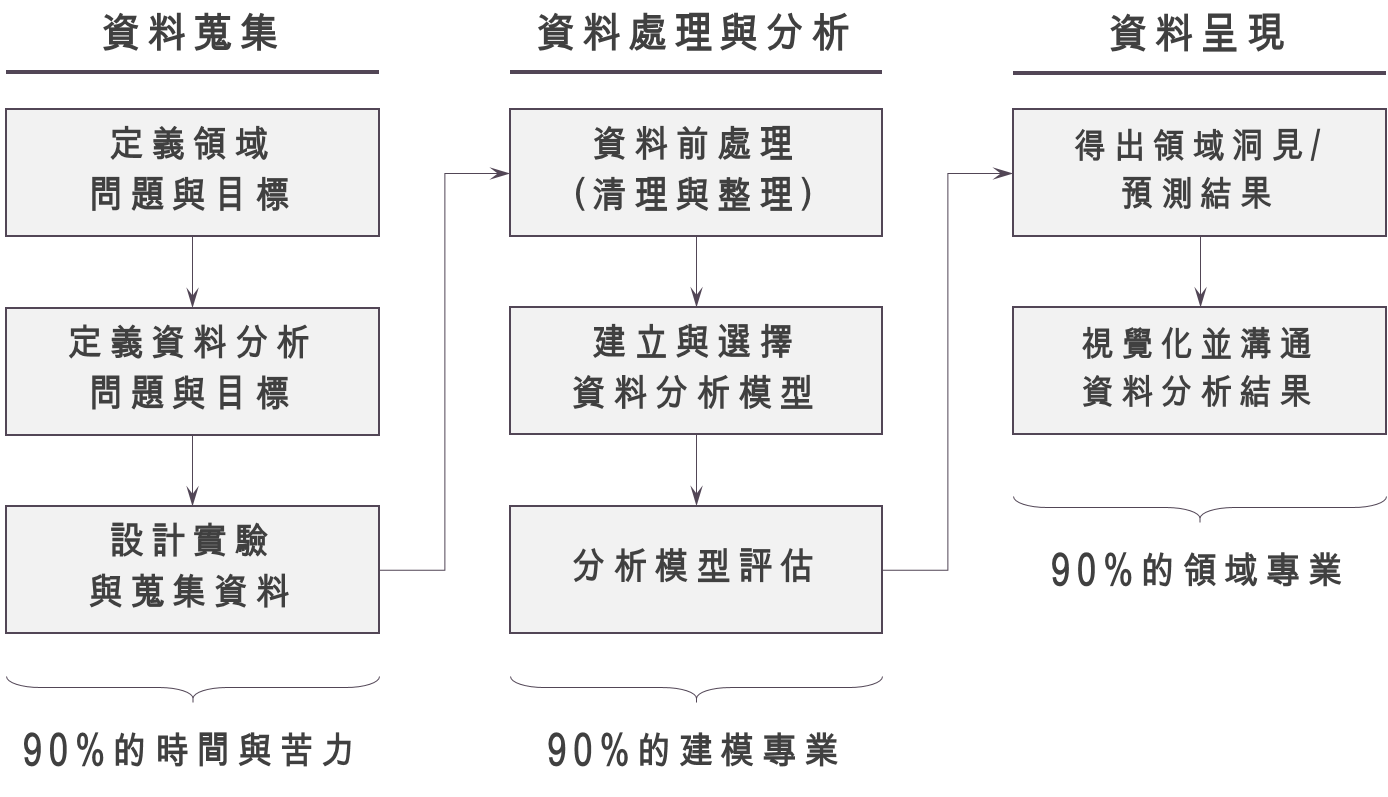
一個資料分析專案的成敗,其實在於資料分析的第一步「Info-in」,如果蒐集到無法回答問題的資料,或是蒐集到「不可靠的資料」,後面建立了再潮的模型,得出再棒的觀點,都是徒勞無功的。這一部份我覺得很考驗資料科學家的能力:能不能有效的與領域專家辨認出資料可以解決的問題,針對領域專家的問題「設計商業/科學實驗」定義出正確的資料分析問題與目標,並規劃資料蒐集的範圍與流程,確保資料來源的可信度,才能讓後面的分析有價值。這個階段除了需要資料科學家對於領域問題的瞭解外,還需要比較大量的時間去蒐集並處理資料,算是整個資料分析過程中最辛苦的地方。
Info-in 的第一步:定義「領域」問題與目標
Info-in 的第一步,是要定義清楚「專業領域的問題與目標」。就自己本身的經驗,常常會有人問:「我現在有一筆ooxx的資料,大概有AAA個樣本,裡面有BB個變數,你能不能幫我從這些資料中找出一些有趣的事情?」我相信這個問題是所有資料科學家心中的痛,我們最專業的地方是資料分析的模型與演算法設計,因此常常會希望跟我們合作的人有明確一點的描述,你資料的「變數」與「樣本」有哪些,對你來說什麼叫做「有趣」,你想要拿「有趣的事情」做些什麼。所以當有人直接叫我從資料找出重要的資訊時,我心中最真實的想法是:我怎麼知道要拿來幹嘛啦!!!但為了保持資料科學家的優雅跟高大上,避免失業,我只能認真與詢問者討論他有哪些潛在的問題,是想要或可以透過資料分析去解決的。
比如說,之前有個專案,是一個期貨交易員朋友詢問,他說他有個各個原油、石油現貨期貨的交易資訊,想問我有沒有什麼東西是可以做的?這時我跟這個朋友聊了一些他在做交易的心得與價值觀後,大概理解他可能會想要朝哪個方向研究,期貨會反映當事人對未來價地的預期,以公式來看期貨價格 $latex F_t$ 與現貨價格 $latex S_t$ ,因為存在 $latex F_t = S_t \times e^{-r(T-t)}$ 的訂價關係,所以沒有什麼大問題,但「原油」與「石油」價格之間的關係是什麼,他倒是很想知道,知道其中的先後關係可以幫助他建立套利的投資組合。
最後與他討論出來的問題定義是:探究「原油價格上升使成本上漲,造成石油價格上升」還是「石油價格上升,因對於未來石油價格有所預期,使原油價格也上升」。「了解專業領域的問題並定義目標」是需要由資料科學家與該領域的專家一起討論,才能定義出重要、能夠被資料分析回答、且值得被回達的問題,如果一開始就將問題訂在探討石油期貨與石油現貨的價格關係,而沒有仔細和我朋友聊聊,其實並沒有辦法幫助我的交易員朋友做交易決策!
Info-in 的第二步:定義「資料分析」的問題與目標
如果說第一步是考驗資料科學家的好奇心與溝通能力,我覺得第二步將非常考驗資料科學家對於各種不同模型及理論的掌握程度。當我們定義出正確的領域問題後,資料科學家將開始思考這個問題該如何被資料解答。這時,我自己先習慣去想這是「解釋」、「個體預測」、還是「趨勢預測」的問題,定義好之後,會再去思考目前現有的統計方法或是機器學習演算法中哪些符合這個情境,然後確認這個方法能夠正確的回答被提出的領域問題。
以前面的石油與原油價格間的關係為例子,我先將這個問題定義成「解釋」─了解統計上的因果關係,接著價格是一個時間序列,所以我會採用時間序列分析,要了解因果關係,在統計上有一種類型的關係較做 Granger Causality,他的概念是:因變數可以增加果變數的預測能力,但果變數沒辦法增加因變數的預測能力。這樣的設定能夠回答「是哪一種的油價先上升?」雖然不能夠探討其中的機制,但對於建立套利投資組合,能夠預測是最重要的,因此這樣的統計方法已經足夠回答交易員好友的問題了!當然,如果你合作的人是行銷人員,可能會運用到的是資料探勘技巧,如果你在網路公司工作,可能會用到大量的機器學習演算法,因此這個階段相當需要對於模型理論與限制足夠了解的資料科學家。
Info-in 的第三步:開始蒐集資料
「蒐集資料」看起來不是件難事,想了解消費者偏好,發個問卷調查就有資料了,想要看使用者的資料,去資料庫撈就有了,但其實「蒐集資料」是件很麻煩的事情。首先,如果是做問卷調查 (survey sampling),如何設計一個可信的問卷問出你真正想知道的資訊,如何正確的選擇調查母體,如何進行抽樣才能夠消除潛在誤差,這些需要統計學家的規劃。如果是在網路公司工作,每天可能都會有數百GB的資料產生,裡面的欄位可能時常會有缺失值 (missing value),也有可能蒐集不到需要的資料,更常的情況是以為蒐集到的資料是正確的,但其實是有問題的,也就是Big Data 4V中的 veracity 的問題。
在資料科學家思考好要建立什麼樣的模型後,資料科學家會與領域專家、市場調查研究員、或是後台工程師一同規畫並定義需要蒐集的變數,在蒐集中有兩件相當重要的事情:一是確認蒐集到的變數是模型需要且可以回答領域問題的,二是確保資料的真實性與可信度。其中一是比較小的事情,當你發現蒐集到的變數是不需要的,拋棄掉就好,如果沒辦法回答領域問題,再重新蒐集即可,如果蒐集不到真正可以回答領域問題的變數,還可以用其他代理變數去比較跟 benchmark 。
真正麻煩的其實在於「確保資料的真實性與可信度」,一來是在我們蒐集資料前我們不一定知道真實資料的樣貌,二來是如果我們以為蒐集到的資料是正確的,接下來做分析並得出結論,這些結論很可能會跟事實完全相反!因此,在蒐集資料的時候資料科學家應該要跟領域專家試著寫清楚變數的定義,並產生假的樣本資料讓蒐集者知道自己該蒐集什麼資料,蒐集的途中也要不斷檢視資料是否符合預期。由此可想而知,「資料蒐集」可以說是整個資料分析流程中耗時人力與時間第二大的步驟!(最花時間的應當是資料清理與轉換)
下一步:Info-process 資料分析
Info-in 是資料分析專案的第一步,也是關乎整個專案成敗中最重要的一步。大鼻在這裡只是簡單分享自己在做專案和實習時的經驗,非常希望有各路達人也來說說自己的想法。在資料蒐集的流程中,「定義領域問題」是我認為最重要的一步,而「確保資料的真實與可靠性」則是資料分析成敗的決戰點,這些步驟需要許多不同專業的人互相合作,才能解決實務上的問題。我認為,不應該強求成為一個「全能的資料科學家」(畢竟我並不是天才),我想成為的是一個「T 型資料科學家」,對於所有資料分析的議題有基本認識,對於統計、電腦科學、或是領域知識其中一項有著朝深入的了解。
下一篇我將會切入「資料分析」的範疇,討論在解釋、個體預測、趨勢預測時,有哪些資料分析的流程與邏輯是需要注意的。有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
大鼻觀點:https://www.facebook.com/davidperspective/
思緒清晰,論述分明,同樣為大數據分析工作者很有共鳴阿!
想看後續的文章QQ覺得寫得超級好!