
今年我們公司與清大的 Business Analytics Using Data Mining 課程合作,透過資料分享讓學生能夠實際從問題定義到運用不同的演算法解決商業問題。在課程中,許多學生的主題都是「行銷定位策略」(Targeting Strategy),比如說:「針對最有可能流失的客戶,提供額外的誘因如折價券」、「針對下個月可能會購買的客戶,提供折價券」等類型的問題。在實務上,我們的確時常遇到希望能透過更精準的定位,減少客戶的流失或是提升客戶的購買意願,然而針對「最有可能流失的客戶」提供額外誘因,有時候可能不是最好的方法−這些客戶有可能不管怎麼樣都不會回來了,不論你有沒有提供他額外誘因。因此,今天想要跟大家介紹更好的方法−以「增益」的定位策略,細節可以閱讀完整的論文 Retention Futility: Targeting High-Risk Customers Might Be Ineffective 。
「客戶流失」是許多訂閱制 (subscription-based)服務公司的一大問題,比如說:Netflix 會擔心註冊會員會不會取消註冊、Google 會擔心你會不會終止 Youtube Premium 的服務、中華電信會擔心客戶會不會終止合約轉移到遠傳等等。與交易制 (transaction-based) 公司不同的是,訂閱制的會員一旦取消訂閱,很少有機會會再回到你的平台重新訂閱。因此,這類公司非常在意如何留住使用者,維持較高的客戶留存率 (customer retention rate)。通常,為了留下可能會離開的客戶,針對有較高流失風險 (customer churn risk) 的客戶,想辦法說服客戶留下,比如說:Youtube 可能會提供你額外兩個月的免費期、中華電信會主動聯繫你說明中華的好處等等,因此客戶流失預測變成這類公司的重要問題,Kaggle 上也有 Telecom Customer Churn 的資料集合供大家練習。
客戶流失預測 (Customer Churn Prediction)
實務上,客戶流失預測通常是一個分類問題 (classification),令 $latex Y_{i,} = 1$ 代表客戶 $latex i$ 終止我們的服務,$latex Y_{i} = 0$ 代表持續使用我們的服務,$latex \mathbf{X}_{i}$ 代表客戶 $latex i$ 的相關特徵 (features),則客戶流失預測其實就是在估計 $latex \mathbb{P}(Y_{i} = 1 | \mathbf{X}_{i})$。想建立一個好的分類模型有些挑戰,比如說:選擇的特徵需要能夠作為流失的「領先指標」,如果流失率不高的話可能會有不平衡資料的問題等,但這些挑戰其實也有滿多對應的建模方法可以幫忙解決,因此不算是一個太困難的資料科學問題。
一般建立完預測模型後,公司會針對預測流失風險較高(也就是 $latex \mathbb{P}(Y_{i} = 1 | \mathbf{X}_{i})$ 較高)的客戶,做比較積極的流失管理,因此在進行模型評估時,我們時常會用 Gain Chart 與 Lift Chart 衡量模型的指標。其中,Gain Chart 衡量的是:「如果我取模型預測風險最高的前 X % 的客戶,能夠捕捉到多少的流失客戶」,因此 X 軸通常是十分位(預測風險在前10%、20%、…的消費者),Y 軸是「前 X% 高風險的客戶,已經包含了 Y% 的流失客戶」;Lift Chart 衡量的是:「如果我取模型預測風險最高的前 X % 的客戶,捕捉到的流失客戶與隨機取 X% 的客戶捕捉的留失度差了多少」,因此 X 軸一樣是十分位,Y 軸則是「前 X% 高風險的客包含的流失客戶佔總流失客戶的比率 (Y%) / 隨機取 X% 的客戶包含的流失客戶佔總流失客戶的比率 (也就是 X%)」。
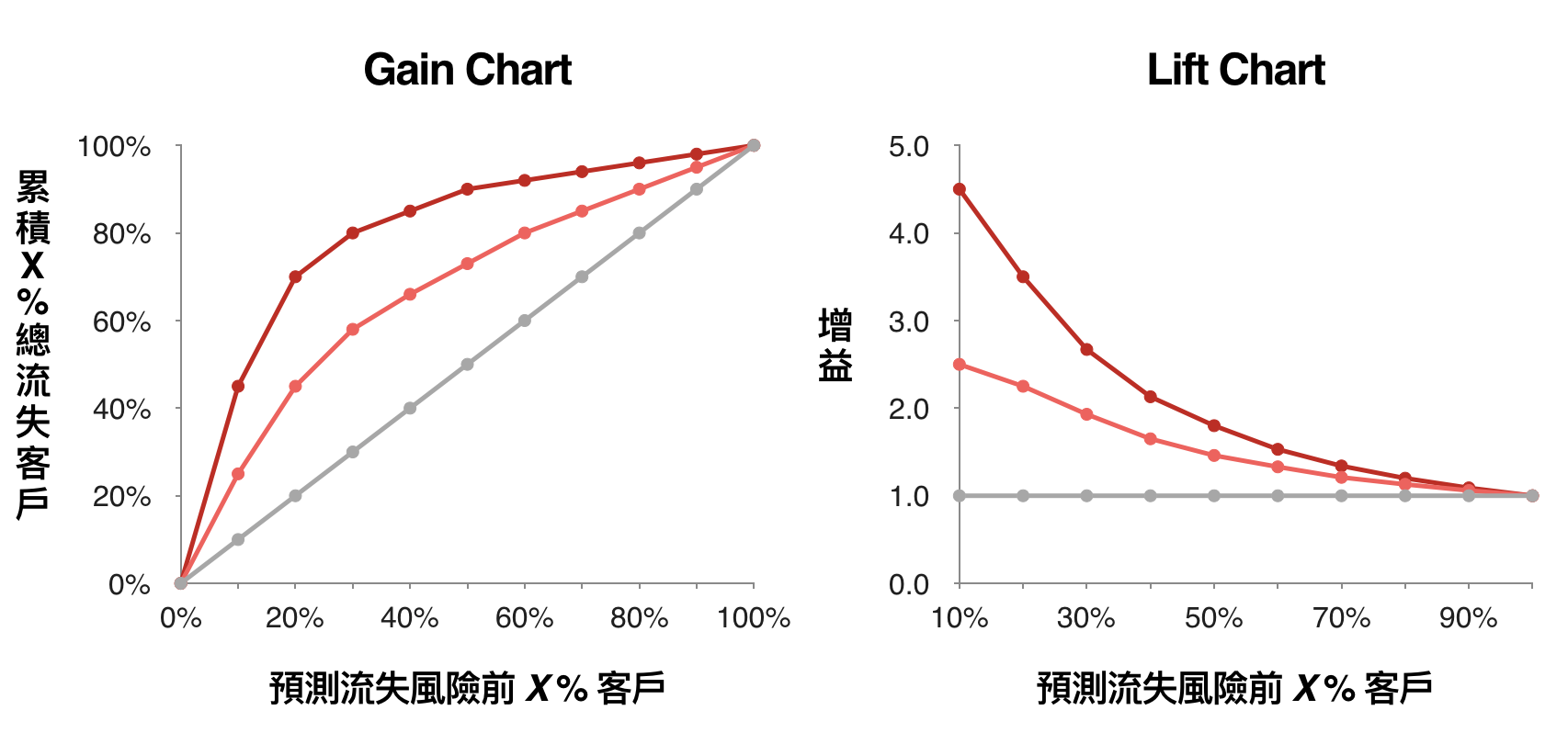
以「增益」(Lift) 為基礎的流失管理
以「流失風險的高低」來排序流失管理的先後順序聽起來固然合理,但並不一定是個好方法,甚至有可能造成反效果。比如說,假設有一個電信業者發現某個客戶可能約到期而且有可能會換到另一個電信,因此打電話主動談起續約的事情,搞不好會激起消費者去研究不同電信業者方案,使該客戶流失的風險提高。相反的,如果主動通知低風險客戶進行換約,他們有可能會提早決定續約,反而降低了該客戶流失的風險。因此,Eva Ascarza 教授在論文引入了「增益」(Lift) 的觀念,建議公司在進行客戶流失管理時,應該以「被定位進行流失管理後,流失風險降低的程度」作為優先順序安排的基礎,基於這樣的觀念,我們建模的目標不再是估計 $latex \mathbb{P}(Y_{i, t} = 1 | \mathbf{X}_{i,t})$,而是估計 $latex Lift_i = \mathbb{P}(Y_{i} = 1 | \mathbf{X}_{i}, T_i = 1) – \mathbb{P}(Y_{i} = 1 | \mathbf{X}_{i}, T_i = 0)$,其中 $latex T_i = 1$ 代表客戶在 $latex t$ 之前有收到流失管理的相關活動,$latex T_i = 0$ 則代表沒有收到相關活動。
務上要怎麼估計「增益」呢?在資料搜集部分,我們會先抽取一組客戶的隨機樣本 (random sample),將這些客戶分成實驗組 (treatment group) 與對照組 (control group),進行先行試驗 (pilot campaign),觀察在收到活動 $latex T$ 後實驗組的表現,估計以用來估計增益 $latex Lift_i = \mathbb{P}(Y_{i} = 1 | \mathbf{X}_{i}, T_i = 1) – \mathbb{P}(Y_{i} = 1 | \mathbf{X}_{i}, T_i = 0)$,在論文中是使用 Uplift Random Forest 模型進行估計的,如果想要了解更多增益估計的細節,可以參考論文:Causal Inference and Uplift Modeling A review of the literature。建立完成增益模型 (uplift model) 後,針對其他不包含在先行試驗的個體,預測他們收到活動後的增益,以提供後續發送活動的依據指標。論文稱這樣的管理為「主動式流失管理」(proactive churn management),透過先行試驗以及增益預測,做到更好的管理機制。
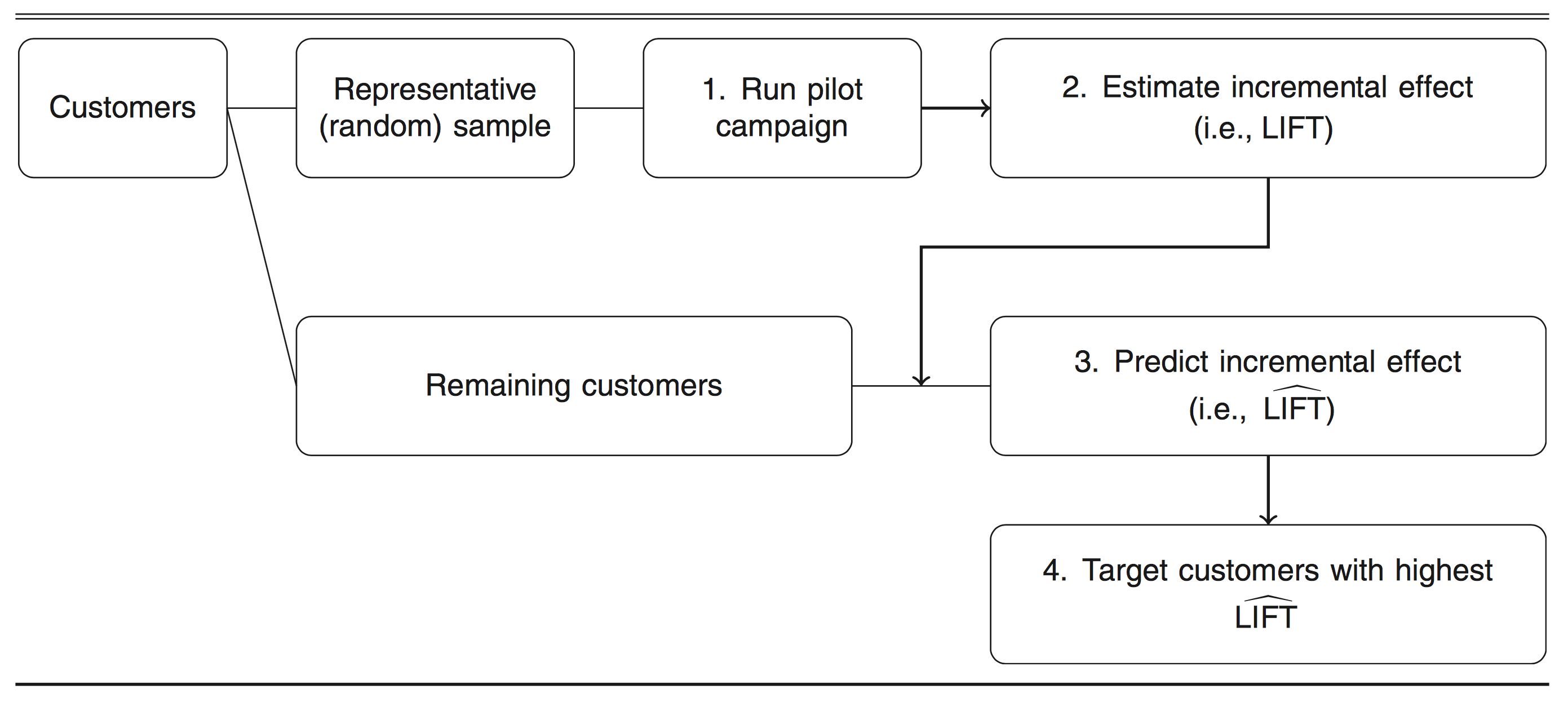
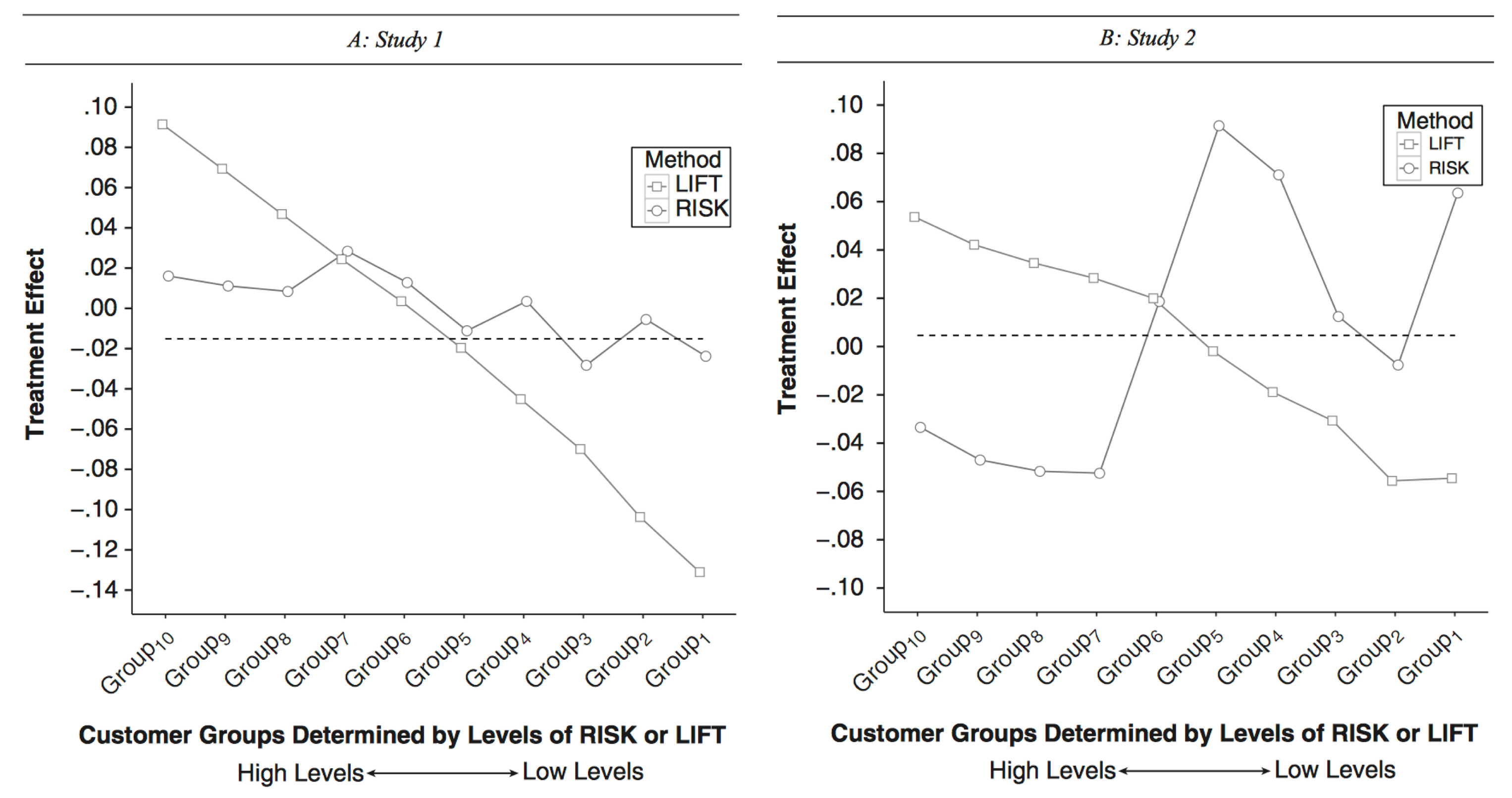
實際應用的表現
在論文中,教授有透過與公司合作做了兩次不同的實驗,其中一個公司是中東的無線網路提供商,測試的活動是「客戶在儲值時,額外提供 free credit」,另一個是北美會員制公司,測試活動則是「在續約時,加入額外的續約禮」。教授在論文中分析了「按照流失風險高低」(平分為 10 組)以及「按照預期增益高低」(平分為 10 組),實驗組與對照組實際流失率的差異(也就是活動成效 (treatment effect)),其中 Group 10 代表風險(或增益)最高的組別, Group 1 則代表風險(或增益)最低的組別。在圖中會發現,「增益」越大的組別,其活動成效也越好,而「風險」越大的組別在研究 2 中該活動反而有較強的負面影響 (Treatment Effect < 0 代表實驗組的客戶流失率反而更高)。另外,在論文中也有進一步分析,不同「客戶特徵」對於「增益」以及「風險」可能會也不同的影響,比如說,在研究二中客戶使用該服務的時間 (tenure) 越長的人,其流失風險越高,但反而是使用該服務時間越少的客戶其增益越高。
如果你們的公司也有在做客戶流失管理,而且也是以「高風險」為主要定位目標的話,建議可以仔細研讀這篇論文,試圖改為以「增益」以及「先行試驗」為基礎的主動式管理方法,說不定能大幅改善公司客戶流失管理的成效!有關 David’s Perspective 的最新文章,都會發布在大鼻的 Facebook 粉絲專頁,如果你喜歡大鼻的文章,還請您不吝嗇地按讚或留言給我喔!
大鼻你好
你的部落格對我們的團隊有很大的啟發,不知道有沒有機會邀請你來幫我們上課呢?
謝謝