

以前在 CHOCOLABS 實習的時候,常常要處理「Tag 標籤」的資料 ─ 因為 CHOCOLABS 的主打 app「追劇瘋」裡面是使用者看連續劇的紀錄,以及各個連續劇的「Tag 標籤」,比如說是古裝劇、職場劇之類的,所以時常要透過分析這兩種類型的資料來得到有用的商業洞見。之前有讀者說,想看看大鼻是分析資料的實際案例,所以就決定分享一些我常用的分析方法。當然,為了確保商業機密,我只示範非常簡單,沒有很多insight的方法給大家看 XD 這些方法也沒有實際應用在 CHOCOLABS 的專案中。
資料前處理 ─ 找出電影特徵矩陣並與評分合併
根據維基百科,MovieLens 是一個推薦系統和虛擬社區網站,其主要功能為應用協同過濾技術和用戶對電影的喜好,向用戶推薦電影。該網站是GroupLens Research實驗室的一個項目,GroupLens Research實驗室隸屬於美國明尼蘇達大學大學計算機系,MovieLens創建於1997年。這個實驗室有公開他們蒐集到的資料給大家下載,在這裡我只用最小的資料ml-latest-small.zip,想要下載這些資料的話可以去他們的網站下載喔。
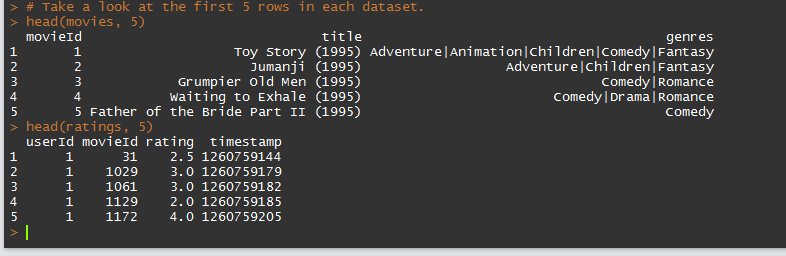
首先,在這篇文章中會用到兩個檔案,一是 movies.csv,裡面有電影的id、名稱與風格(genre),另一個是users.csv,裡面有使用者的id,以及他們對不同電影的評分。先用 R 讀入資料,並且把兩個資料集合的前 5 行叫出來看。
[code language="r"]
movies = read.csv("movies.csv")
ratings = read.csv("ratings.csv")
# Take a look at the first 5 rows in each dataset.
head(movies, 5)
head(ratings, 5)
[/code]
兩個檔案的前 5 行分別如下所示,可以看到的是 movies 資料集合中,他把電影的類型存成一整串的自串,所以我們第一步應該是要把這些字串切開來,才有辦法做分析。
為了要把字串切開,我們會用到"data.table" 這個套件中的函式,切開的程式碼如下:
[code language="r"]
# Split the genres string to several columns.
library(data.table)
genres = as.data.frame(tstrsplit(
as.data.frame(movies$genres, stringsAsFactors=FALSE)[,1],
‘[|]’, type.convert=TRUE), stringsAsFactors=FALSE)
colnames(genres) <- c(1:ncol(genres))
head(genres, 5)
[/code]
同樣的我們可以看到,切好的結果存在genres這個資料框架中,如下:

但是,這樣切開來的資料,我們還是沒辦法做分析,所以要透過「one-hard encoding」把這些類型標籤轉成數字的形式。比如說,第1部電影要有一個叫做"Adventure"的變數,其值為1,也要有"Romance"這個變數,其值為0。寫一個簡單的 for-loop 就可以做到這件事:
[code language="r"]
# Get movie features through one-hard encoding.
genre_list = c("Action", "Adventure", "Animation", "Children", "Comedy",
"Crime","Documentary", "Drama", "Fantasy","Film-Noir",
"Horror", "Musical", "Mystery","Romance","Sci-Fi", "Thriller",
"War", "Western")
genre_matrix = matrix(0,nrow(genres),length(genre_list))
colnames(genre_matrix) = genre_list
for (i in 1:nrow(genres)) {
for (c in 1:ncol(genres)) {
genmat_col = which(genre_list == genres[i,c])
genre_matrix[i, genmat_col] = 1
}
}
genre_matrix = as.data.frame(genre_matrix)
colnames(genre_matrix) = genre_list
genre_matrix = cbind(movieId = movies$movieId, genre_matrix)
head(genre_matrix, 1)
[/code]
切出來的genre_matrix 一行是長下面的樣子,我們終於得到電影的特徵矩陣囉!

最後,只有電影特徵矩陣其實還不夠我們做任何分析,所以還要將電影的特徵矩陣跟使用者評分合併在一起,這聽起來好像夭壽難,其實只要用 merge 函式就可以辦到囉!
[code language="r"]
# Combine ratings and genres matrix
users = merge(ratings, genre_matrix, by.x = ‘movieId’, by.y = ‘movieId’)
head(users, 1)
[/code]
得出來的users資料框架的一行就是我們真正要進行分析的資料集合囉!

意思意思的探索性資料分析 – 了解不同標籤的評分
整理好資料後,MovieLens想說要自己拍一部電影(?),因此想知道哪種類型的主題是目前評分比較高的,此時我們可以用 plyr 套件來整理資料,算出各個genre的平均評分。(ps: 其實 dplyr 或是 tidyr 是效能比較好的套件,但現在資料少用plyr就可以了!)
[code language="r"]
library(plyr)
genres_rating = NULL
for (i in 5:length(users)) {
genres_rating = rbind(genres_rating,
data.frame(genres = colnames(users)[i],
ratings = users[users[,i]==1,3]))}
summary = ddply(genres_rating,.(genres),
summarise, mean_ratings = mean(ratings))
[/code]
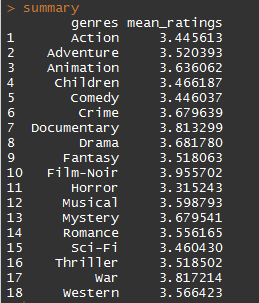
在這裡,大家可以把summary 這個資料框架叫出來看一看,就會發現評分比較高的genre 是黑色電影Film-Noir,指第二次世界大戰以後出現的一種都市化美國類型片,這種影片突出一個宿命的、令人絕望的世界,在這個世界裡,擺脫不掉簡陋的城市街道、孤獨和死亡。從風格上來說,黑色強調低調和高調的光線以及強烈的恐怖和妄想狂氣氛。(其實我不知道黑色電影是什麼,這是google大神說的。)
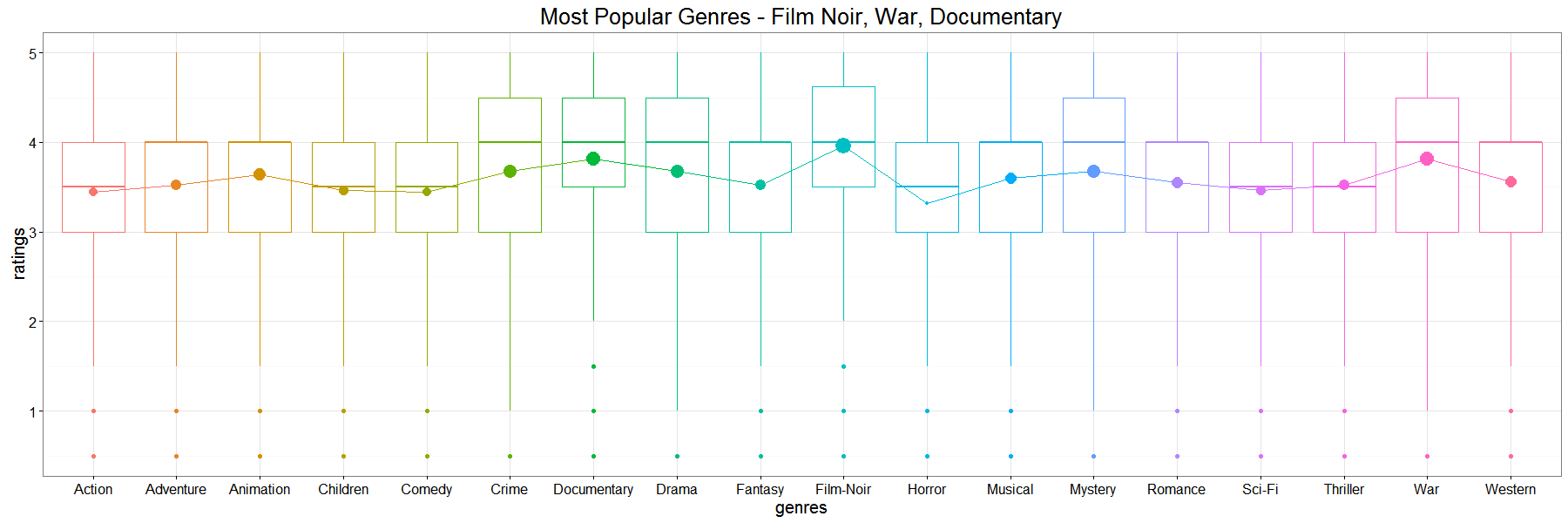
當然給出這一個黑色畫面後,David 就被 MovieLens 的人(?) 說:你怎麼一點美感都沒有!!!所以我只好再用ggplot2畫一張比較漂亮的圖。ggplot這個名字有人覺得很好笑,但其實他的意思是The Grammar of Graphics,原來這是一本書,而這個套件是照這本書的理念寫成的!
[code language="r"]
library(ggplot2)
ggplot(genres_rating, aes(x=genres, y=ratings, colour = genres)) +
geom_boxplot() +
geom_line(data = summary, aes(x = genres, y = mean_ratings, group = ‘grey’)) +
geom_point(data = summary, aes(x = genres, y = mean_ratings,
colour = genres, size = mean_ratings)) +
theme_bw() +
labs(title = "Most Popular Genres – Film Noir, War, and Documentary") +
guides(colour=FALSE, size = FALSE) +
theme(axis.text = element_text(size = 12),
axis.title = element_text(size = 15),
title = element_text(size = 16))
[/code]
大鼻在這裡選擇用盒狀圖呈現,沒有為什麼,只是我覺得比較漂亮絢麗而已 XDD 一般來說盒狀圖是用來呈現分配的,但評分是從0-5分每0.5分一個級距,因此分配沒什麼好差很多的,但我還是意思意思畫給大家看!
意思意思的機器學習 – 用 genres 預測評分
最後,我們可能會想要做一個推薦系統,預測一部電影在給定genres下,會得到高評分還是低評分?在此我定義(自己訂的) 高分代表rating > 3 是高分 (label = 1), <= 3 則是低分(label = 0)。用 ifelse 函式可以很輕鬆地得到label (就跟EXCEL的IF函式用法完全一樣!) 所有的評分紀錄中,有 62106 筆資料 label = 1,有 37898 筆資料 label = 0 ,還算平衡啦!接著把資料分成訓練集合(training set)跟測試集合(testing set) ,在這裡我實在很懶得去做參數選取(parameter tuning),所以就不用分驗證集合(validation set),畢竟是意思意思的機器學習 XD 這裡是用2/3 的資料當作訓練集合!
[code language="r"]
# Create Binary Ratings
users$label = ifelse(users$rating > 3, 1, 0)
# Devide into training and testing data
train_idx = sample(1:nrow(users), floor(nrow(users)*2/3))
train_x = as.matrix(users[train_idx, 5:22])
colnames(train_x) = colnames(users)[5:22]
train_y = users[train_idx, 23]
test_x = as.matrix(users[-train_idx, 5:22])
colnames(test_x) = colnames(users)[5:22]
test_y = users[-train_idx, 23]
[/code]
分好之後,我選擇用非常好用的 xgboost 套件來做,他做 gradient boosting decision tree真的很快,當然tune參數是要點技巧,在這裡我也就隨意地亂選 XD
[code language="r"]
# Fit a Gradient Boosting Tree
library(xgboost)
model = xgboost(data = train_x, label = train_y, max.depth = 20,
eta = 0.5, nround = 30, objective = "binary:logistic",
min_child_weight = 5)
test_y_hat = ifelse(predict(model, test_x) > 0.5, 1, 0)
mean(test_y != test_y_hat)
[/code]
做出來可以看一下 training error 35.46%,testing error 36.30%,好像沒有overfitting,我們就得過且過吧 XD 不過從這麼模型大致上已經可以比較好的決定要拍哪些類型的電影會比較好,你可以把電影的類型當作 input,預測出來如果被評為好的機率夠高,就還okay啦!

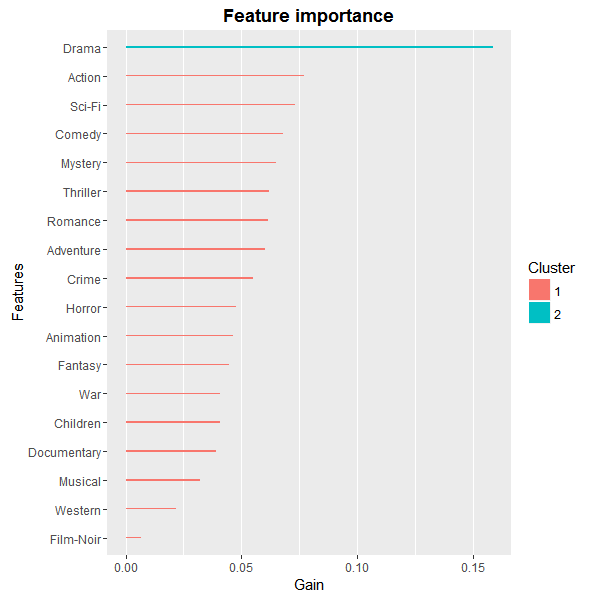
最後我們就隨意的畫一下 tree model大家最愛的變數重要性(variable importance) 吧!實際上在用的時候,大家一定要記得去查 gain 在 xgboost 套件裡面的定義喔!這個就當作給大家的作業吧!(自己懶得解釋XDDDD)
[code language="r"]
library(Ckmeans.1d.dp)
importance = xgb.importance(feature_names = colnames(train_x), model = model,
data = train_x, label = train_y)
xgb.plot.importance(importance_matrix = importance)
[/code]
令人傻眼但也不意外的是,居然「drama」是最重要的變數!但連續劇就是很會爛尾,感覺的確是連續劇是電影會有差!
結論:意思意思,但滿有趣的
這篇文章其實沒有要認真給一些insight,雖然我寫這篇文章花了一小時,但跑上面分析只花了半小時 XD 其實在這裡特別想要跟大家宣揚,R很好用!!!!!大家快來學R!!!!!如果你喜歡大鼻的文章,或是你看到這篇文之後覺得資料科學很好玩,拜託!!快來一起成為資料科學家,以及按大鼻觀點讚!趕論文去~ 愛大家!
hi~
看完這篇文章,單純分享我的資料處理方式~互相參考看看
movies = read.csv(“D:\\016288\\Desktop\\ml-latest-small\\movies.csv")
ratings = read.csv(“D:\\016288\\Desktop\\ml-latest-small\\ratings.csv")
#把genres切割出來
genres<-strsplit(movies$genres,'[|]')
genres_total_length=0
for(i in 1:length(genres)){
genres_total_length=genres_total_length+length(genres[[i]])
}
movie_id<-rep(NA,genres_total_length)
movie_feature<-rep(NA,genres_total_length)
movie_feature_value<-rep(1,genres_total_length)
v<-data.frame(movie_id,movie_feature,movie_feature_value)
index=0
for(j in 1:length(genres)){
for(k in 1:length(genres[[j]])){
index=index+1
v[index,1]=movies$movieId[j]
v[index,2]=genres[[j]][k]
}
}
#每一部電影對應到每一種類型(1,0)
v2<-cast(v, movie_id ~ movie_feature)
#check 每一個變數含NA值的個數
sapply(v2,function(x) length(!x[is.na(x)]) )
#把NA值變0
v2<-sapply(v2,function(x) ifelse(is.na(x),0,x) )
v2<-as.data.frame(v2)
#合併評分data
v3<-merge(ratings,v2,by.x = 'movieId',by.y = 'movie_id')
#算每一類型電影的平均rating→先變為row data再使用dplyr
v3_melt%
filter(value==1) %>%
group_by(variable) %>%
summarise(mean_rating=mean(rating))