

「資料科學」(Data Science) 是近三年來相當火紅的議題,資料科學跟傳統的統計學有什麼不一樣呢?資料科學家為什麼會被譽為21世紀最性感的職業呢?在這裡先引用《維基百科》對於資料科學的定義:
Data science is an interdisciplinary field about processes and systems to extract knowledge or insights from data in various forms, either structured or unstructured, which is a continuation of some of the data analysis fields such as statistics, machine learning, data mining, and predictive analytics, similar to Knowledge Discovery in Databases (KDD).
資料科學的目標,是從「資料」中萃取出「有用的資訊」,不論你的資料是臨床試驗蒐集到的小樣本,還是Ptt鄉民的風向留言,甚至是手機應用程式點擊蒐集到的log檔,資料科學家不斷試圖從繁雜的資料中找出資訊,並將這些資訊運用至商業、醫療、科技、人文、物理、經濟、生活等各個領域,解決大家的疑難雜症。其實,統計學可說是資料科學的始祖,早在西元前五世紀敘述統計的方法就已經被人們應用在生活中,大約在十七世紀統計學家已經開始運用抽樣調查進行推論統計。
在資料科學的發展進程中,數學家、統計學家、電腦科學家、領域專家等都扮演著重要角色,也因此出現了「統計學」、「機器學習」、「資料探勘」等不同名詞。不同公司、不同崗位的資料科學家,也常常會運用不同的資料科學方法論來解決問題,雖然現在的資料科學演算法有千百種,但總結來說這些方法的目的大概有三個大類(註1):解釋(explanation)、個體預測(prediction)、趨勢預測(forecasting)。
「解釋」(explanation):與因果關係共舞的科學方法
過去數十餘載中,許多頂尖的統計學家都在研究「如何用資料了解變數/個體間的相關結構」以及「如何用這些關聯性解釋因果關係」,為什麼「解釋因果關係」是如此重要的目標呢?
首先,因果關係能夠幫助我們進行更好的決策。假想你是一個樂善好施的富商,你時常將錢借給有需要的人,並希望他們在解決困難時能夠把錢還給你,這時你一定會思考到底「打電話催繳」、「寄發存證信函」、「登門訪問」三個行為,是否能夠讓欠錢的人準時還錢?以及哪一個行為比較容易讓借錢的人準時還錢?這時,我們想探討的是「因變數」催款行為以及「果變數」還款金額間的關係。這時,資料科學家可以分析過去催款的資料,運用「變異數分析」(Analysis of Variance, ANOVA),解釋「因變數」與「果變數」的相關性。一旦相關性清楚了,因果關係被解釋了,富商就知道應該要用哪一種催款行為能夠讓他拿回他的錢。
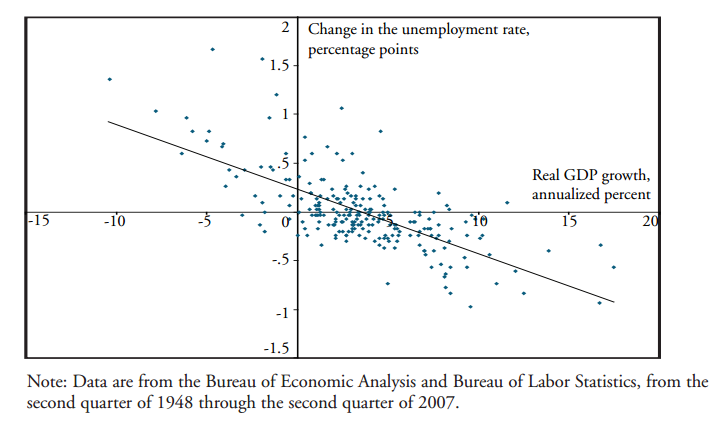
此外,過去大部分的科學家都認為:「可以解釋就代表可以預測」,因此可以透過資料「歸納」(induce) 出「因變數」與「果變數」之間的關聯,接著透過資料的「演繹」(deduce)去預測未來。經濟學家奧肯 (Okun) 「實質GDP成長率」與「失業率變化」的資料「歸納」,也就是運用統計學中的回歸分析(regression analysis),發現兩者間存在著以下關係:
失業率變化 = a – b* 實質GDP成長率,其中 b > 0。
也就是說,當一個國家的實質產出(real output,通常以實質GDP作為量度標準)成長率越高時,其失業率將會隨之降低,因此當一國的經濟產出持續成長時,將能夠大大改善該國的失業率。因此,透過「演繹」,我們知道只要實質GDP成長率決定,失業率變化就可以被預測了!下圖是美國堪薩斯州聯準會分析1948年第二季至2007年第二季的季資料得出的結果(註2),資料分析不但證明了「實質GDP成長率」與「失業率變化」間的因果關係,更能夠幫助經濟學家預測失業率變化。
「個體預測」(prediction):讓機器成為你的算命師
人類一直喜歡推算未來,算命師在算命前常常會透過蒐集手相來預測你的命運,某些厲害的算命師可以預測的非常準。在「機器學習」(machine learning)大鳴大放的時代,「機器」就是你的算命師,「特徵」(feature) 則是重要的資訊,也就是此處的手相,而算命師不外傳的絕活,就是所謂的「演算法」(algorithm)或「模型」(model)。整合在一起,「機器學習」就是讓「機器」運用「演算法」進行「預測」,也就是算命師啦!
算命師在看手相算命的時候是否有辦法解釋「手相」與「命運」間的關係呢?其實是沒辦法的,就算我們能夠知道生命線可以看你活到幾歲,也沒辦法回答「為什麼那條線代表的是壽命」。因此,我們在進行「預測」跟「解釋」最大不同之處在於,我們比較不在乎為什麼,更關心預測的準不準。前面提到過,過去大部分的科學家認為「可以解釋就代表可以預測」,但「不能解釋就不代表不能預測」。另外,算命師通常看的是「個體」的「命運」,而機器學習表較常有的情況也是觀察「個體」(individual)的「性質」(property)。
舉例而言,信用卡公司可以透過消費者的「特徵」,如:過去的交易記錄、目前的財務狀況、目前的信用評等等資訊,運用「機器學習」中分類 (classification) 相關的演算法,「預測」消費者未來90天內的是否會違約。此時,我們的重點將在於「極小化預測誤差」,而不是「解釋特徵與預測結果間的關係」。

「趨勢預測」(forecasting):鑑往知來的趨勢預測
其實「趨勢預測」(forecasting) 跟「預測」(prediction) 都想要推估「未來」的可能。然而,有別於「預測」想做到的是透過許多不同的個體,來預測下一個新個體的性質,「趨勢預測」希望能夠反映出一個變數隨著時間經過的趨勢。因此,只要有一個變數我們就能進行「趨勢預測」,但這個變數要是一個「時間序列」(time series) – 隨著時間經過而改變的變數。
許多時候,將每一個時間點視為一個新個體,機器學習也能夠進行趨勢預測,但機器學習比較難捕捉到一個序列的「趨勢」與「週期性」,此外,機器學習常常需要蒐集許多不同的「特徵」,通常「特徵」越多預測的越準,但許多情境我們只能觀察到一個「時間序列」,很難再根據這個序列去蒐集有用的特徵。此外,機器學習也需要透過蒐集許多個體才能夠進行準確的預測(算命師也是看多了手相才會算命的),但「時間序列」的資料常常個體數不夠多,導致機器沒辦法預測的非常準確。
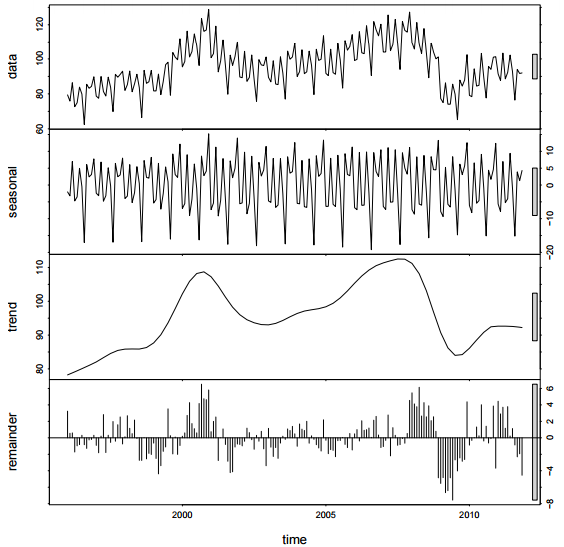
比如說,發電廠為了確保供電穩定性,時常需要進行電力需求的預測,通常只需要根據過去的電力資料,預測下一個月/下一期的電力需求,我們也很能蒐集與「電力需求」相關的特徵,因此我們常用時間序列的方式進行預測,下圖是使用R語言Forecast套件,將歐洲電力需求的時間序列拆分成「季節」、「趨勢」與「殘差」三項。R語言Forecast套件的作者是澳洲蒙納許大學的Rob J Hyndman教授所作,是R語言「趨勢預測」最好用的套件。
所以我說,那也太難了吧!
看到這裡,相信各位對於資料科學的三大目標已經有了基本的認識,當然也可能暈頭轉向,覺得資料科學中也太多東西要學了吧!沒錯,連大鼻踏入這個領域兩年了,也還是暈頭轉向啊!看起來要能「解釋」,需要很好的統計知識與分析邏輯,要能「個體預測」,似乎要很會寫程式跟了解很多演算法,要能「趨勢預測」好像有無窮無盡的時間序列模型可以學。在釐清「資料科學」的目標之後,大鼻認為要成為資料科學家,第一步應該先學會「解釋型」的資料科學技巧,同時培養「推論/演繹」(induction/deduction)的邏輯思辨能力,這樣在後面兩個領域才能夠走的順暢喔!
註1:特徵轉換(feature transfomation)到底算不算是一種「目的」呢?我認為不算,因為大部分的特徵轉換都是為了「解釋」(如:找出共同的因子)或是「預測」(如:將圖片轉換成數字,幫助我們進行辨識)。當然,也有影像處理、訊號轉換等目標,但我認為這跟資料科學的相關性就比較沒這麼強了。
註2:Edward S. Knotek II. How useful is Okun’s law? Economic Review, 2007.
大維,我現在應該也要踏入這個領域,不過是生物資訊的部分,但我對資料科學這領域實在是很沒有概念,而且也沒有統計的基礎,不知道有沒有可以幫助我入門的書啊??
嗨,我通常會建議剛要踏入這個領域的人上以下的課程專項:
https://www.coursera.org/specializations/jhu-data-science
只要一門一門課搜尋點進去註冊就可以不用錢上課喔!我認為上完這個專項還不到專業的程度,但會完整了解資料科學的重要方法,之後會比較知道該怎麼走!
如果是想從基本的機率與統計搭配R語言學起,建議可以用CRAN上的Introduction to Probability
and Statistics Using R,網址如下:
https://cran.r-project.org/web/packages/IPSUR/vignettes/IPSUR.pdf
如果是想學Machine Learning搭配R語言,建議可以使用CRAN上的R and Data Mining: Examples and Case Studies作為研讀素材,網址如下:
https://cran.r-project.org/doc/contrib/Zhao_R_and_data_mining.pdf
如果想學Python的話,建議的用書有:
Introduction to Python for Econometrics, Statistics and Data Analysis
https://www.kevinsheppard.com/images/0/09/Python_introduction.pdf
Machine Learning in Python
https://pythonizame.s3.amazonaws.com/media/Book/machine-learning-python-essential-techniques-predictive-analysis/file/008c0aac-9784-11e5-964d-04015fb6ba01.pdf
好喔~感謝大維,我會先從那個課程專項開始看看
然後語言的話應該會先學PYTHON,我們所上有開課
有問題再來請教你~
歐歐!我覺得很棒!特別喜歡學習方法的建議!這是目前看到覺得架構系統做得最好的了!
謝謝你的讚美!如果有什麼想要特別了解的主題也可以跟我說喔~